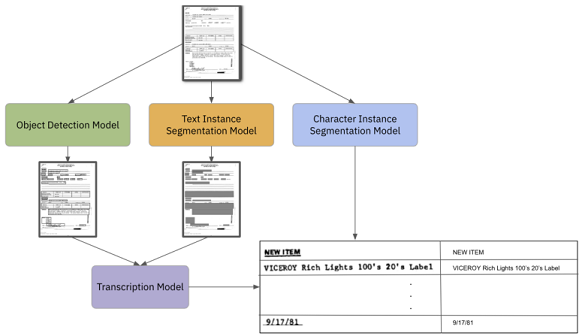
OCR / Document Understanding Survey 논문 리뷰 이번 글에서는 NeurIPS2020의 ML-RSA 워크숍에 등재되었던 OCR 및 문서 이해와 관련된 Survey paper의 주요 내용에 대하여 간략하고 이해하기 쉽게 정리해보도록 하겠습니다. 해당 논문의 제목은 "A Survey of Deep Learning Approaches for OCR and Document Understanding" 입니다. Document Processing & Understanding의 전체 과정 문서 이미지로부터 텍스트를 추출하여 원하는 정보를 최종적으로 가져와 사용할 수 있는 테크닉은 응용될 수 있는 분야가 방대하고 매우 가치가 높은데, 다양한 종류의 문서 이미지에서 위 과정을 잘 수행하기 위해서..