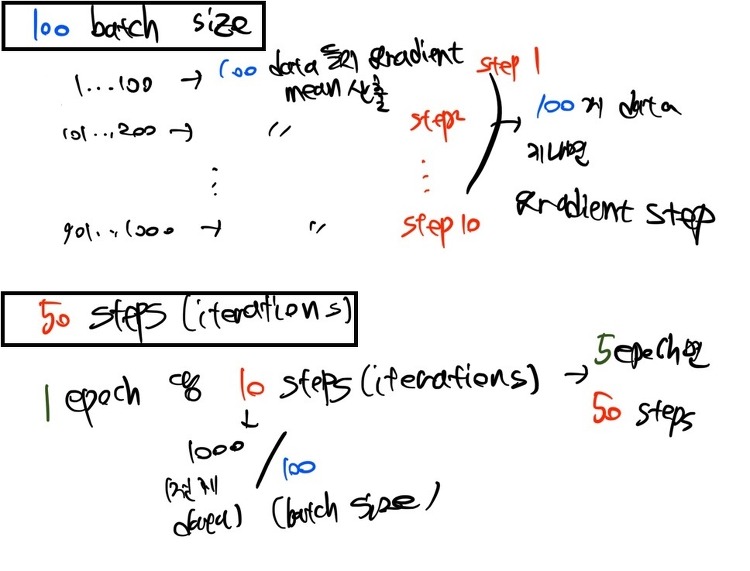
배치 크기가 커지면 학습 시간 및 GPU 메모리 사용량은 어떻게 될까요? 배치 크기가 커지면 학습 시간은 계속 줄어들까요? GPU 메모리 사용량과는 어떤 관계가 있을까요? 우선, 제가 가진 학습 코드를 통해 간단하게 실험해본 결과는 다음과 같습니다. Batch Size = 1 데이터가 약 89000개 정도이므로, 1 epoch 당 89000 스텝이 진행되고, 예상 학습 시간은 1시간 45분 정도였습니다. 모델 파라미터 + 데이터 1개 텐서 = 2207MB 정도의 메모리가 사용되는 것을 보았습니다. Batch Size = 2 89000개의 절반인 약 45000 스텝 정도가 1 epch에 진행됩니다. 학습 예상 시간은 1시간 24분 정도로 약간 줄었으나, Batch Size = 1인 경우에 비하여 절반으로 ..