OCR / Document Understanding Survey 논문 리뷰
이번 글에서는 NeurIPS2020의 ML-RSA 워크숍에 등재되었던
OCR 및 문서 이해와 관련된 Survey paper의 주요 내용에 대하여
간략하고 이해하기 쉽게 정리해보도록 하겠습니다.
해당 논문의 제목은
"A Survey of Deep Learning Approaches for OCR and Document Understanding"
입니다.
Document Processing & Understanding의 전체 과정
문서 이미지로부터 텍스트를 추출하여 원하는 정보를 최종적으로 가져와 사용할 수 있는
테크닉은 응용될 수 있는 분야가 방대하고 매우 가치가 높은데,
다양한 종류의 문서 이미지에서 위 과정을 잘 수행하기 위해서는
컴퓨터 비전 및 자연어 처리의 고도화된 기술들이 통합적으로 사용되어야 합니다.
이를 위한 전체 과정을 총 3단계로 다음과 같이 분할하여 해석해볼 수 있습니다.
1. 문서 이미지 내에서 region 분할
2. 문서 이미지 -> 텍스트 추출(OCR)
3. 추출된 텍스트 -> 원하는 정보(IE)
해당 논문에서는 파트 3~5에 나누어 2 -> 1 -> 3번 과정 순으로 설명하고 있는데,
여기서는 파트 순서를 바꾸어 1~3단계 순서로 내용을 간략하게 정리하여 풀어보도록 하겠습니다.
Step 1 : Document Layout Analysis

문서 이미지 내에서는 그림, 표, 제목, 단락 등의 다양한 구획으로 분할할 수 있으며,
이들을 정확하게 분리해내는 것이 이후 단계를 위하여 매우 중요합니다.
Instance Segmentation for Layout Analysis
기본적인 발상은 pixel 단위로 region category를 예측하자는 것입니다.
Yang et al. 논문에서는 encoder-decoder 방식의 segmentation을 제안하였는데
주요 내용만 요약하자면 encoder 부분에서는 downsampling을 통하여 차원을 줄이고,
decoder 부분에서는 줄여진 차원에서 다시 upsampling을 수행하여 복원을 하는 것입니다.
그리고 디코딩 과정의 last layer에 텍스트 임베딩 정보를 같이 입력해주어
매칭되는 텍스트를 추측하여 최종 segmentation 예측을 진행하는 원리입니다.
이러한 U-Net과 유사한 encoder-decoder 방식이 근간이 되어
이를 변형하여 응용된 연구들이 layout analysis 과정을 위해서 수 차례 수행되었습니다.
Addressing Data Scarcity and Alternative Approaches
그러나, 각 문서 이미지로 부터 구획 및 텍스트 정보를 수작업으로 분리하여
양질의 데이터셋을 만드는 과정은 고되고 비용이 많이 드는 작업입니다.
따라서, 이러한 data scarcity를 해결하기 위한 대안이 몇 가지 있는데 이는 다음과 같습니다.
1. 위의 Yang et al. 논문 기법으로 학습된 모델을 활용하여 unlabeled image로부터
대략적인 feature를 가져오는 것이 가능합니다.
(pre-train된 언어 모델의 높은 성능과 2D positional embedding이 이 과정을 도와줍니다.)
2. label이 있는 데이터를 합성하는 방법이 제안된 적이 있는데, 방법은 다음과 같이 요약됩니다.
랜덤 추출된 200개 배경에서 문서 생성 ->
격자 기반 메소드 사용하여 특정 크기의 컨텐츠 정의 ->
생성 과정에서 gaussian blur나 random image crops 등의 corruption 방법을 활용하여
layout analysis 모델을 더 robust하게 만들 수 있게 함
3. 기존 데이터에서 deformations이나 perturbations을 통하여
data augmentation을 진행하는 방법도 도움이 될 수 있습니다.
Datasets for Layout Analysis
대표적인 layout analysis를 위한 데이터셋으로는
매년 열리는 대회에서 제공하며 퀄리티가 상당히 높은 ICDAR과
문서 파일로부터 생성된 대용량의 DocBank, PubLayNet, PubTabNet 등도 많이 활용됩니다.
Step 2 : Optical Character Recognition(OCR)
우선 OCR은 크게 텍스트 부위를 이미지에서 찾는 Text detection 과정과
찾은 텍스트 이미지로 부터 real text로 변환하는 Text Transcription 과정으로
나눌 수 있습니다.
Text Detection
크게 text의 bounding box의 위치를 학습하는 object detection 방식과
text가 없는 부분은 mask하고 text만 원본으로 남기는 instance segmentation 방식으로
나뉘게 됩니다.
먼저, object detection 방식의 대표적인 기법으로는
Single-Shot MultiBox Detector이나 Faster R-CNN가 효율적인 방법론들을 제시했으며,
텍스트 회귀 기반 detector를 활용한 TextBoxes 등도 큰 기여를 했었습니다.
참고로, 이 방식의 경우 성능 평가는 예측 bounding box 범위가 실제 데이터와 겹치는 부위의
비율의 threshold 이상이면 true positive로 간주하는 IoU 방식을 사용하고,
이 IoU 방식으로 간주된 positive/negative 비율로 F1 점수를 계산하여 진행됩니다.
instance segmentation 방식의 경우는 문서 이미지 내에 텍스트의 비중이 높다는 점을
고려하여 ultra-dense한 상황에서의 segmentation으로 생각해 볼 수 있습니다.
윗 파트에서 다룬 구획 분할과 마찬가지로 기본적으로 픽셀 단위에서 작동하며,
Fully Convolutional Networks(FCN) 등 유명한 segmentation 기법에서 시작하여
다양한 정보를 곁들여 활용하는 TextSnake 기법 등으로 발전하였습니다.
또한, text detection 과정에서 word level의 추출보다 character level의 추출이
모호함이 더 적어 쉬울 수 있다는 의견이 많았는데,
CRAFT, RPN 등 기법에서 시도되어 큰 성공을 거두었습니다.
다만, 일그러진 텍스트에서의 인식 문제 등이 실제 데이터에서는 여전히 존재하는 만큼
아직 넘어야 할 산은 남아 있습니다.
Text Transcription
이제 텍스트 정보를 완전히 가져오기 위해서는 text detection 과정에서 추출했던
일부 이미지 부분을 input으로 주어 real text로 변환하는 과정을 수행해야 합니다.
이는 vacab size 만큼의 종류 중 올바른 텍스트를 찾는 multiclass 분류 문제로도 볼 수 있는데
'elephont'로 인식된 텍스트를 단어의 빈도를 고려하여 'elephant'로 고치는 과정 등도
올바른 텍스트 추출 과정에서 필요할 수 있습니다.
word level로 텍스트를 전사하면 위와 같은 오분류 문제를 어느정도 해소할 수 있으나,
사전에 없는 단어가 등장 시 문제가 될 수 있습니다.
반면, character level의 경우 새로운 단어에 대한 예측도 가능해지지만
오분류에 대한 robustness가 상당히 떨어질 수 있을 것입니다.
따라서, 대안으로 토크나이저 방식처럼 subword level의 예측 방식이 제안되고 있습니다.
convolutional image에서 추출했던 feature에서 decodeing 방식으로 텍스트를
전사하는 방식이 많이 사용되는데 LSTM이나 GRU 같은 RNN 기반 모델이 주로 사용되었습니다.
디코딩 방식으로는 자연어 처리에서 텍스트를 생성하는 기본 원리인
cross entropy loss 기반 beam search 활용 greedy 디코딩이 사용되기도 했었고,
repeated character 출력에 강하여 speech에서 많이 활용되는 CTC loss도 제안되었습니다.
End-to-end models
detection 및 transcription 과정을 한 번에 학습하는 end-to-end 구조의 모델이
때로는 더 효과적이기도 합니다.
(예시로 만약 최종 예측 확률이 낮다면 텍스트 detection에 실패했음을 암시할 수 있으며,
end-to-end 구조로 학습할 경우의 signal로 개선을 시킬 가능성이 꽤 있습니다.)
가장 심플하면서 많이 쓰이는 방법으로는 detection과 transcription 모델을 각각 가져와
이어 붙인 뒤 학습을 진행하는 방법으로,
FOTS와 TextSpotter을 이어 붙여 학습 시킨 사례가 있습니다.
이 방법이 오류 감소에 기여를 어느 정도한 바가 있지만, 그래도 두 모델을 따로 훈련시키는 것은
모델의 유연성 강화 및 병목 현상을 잘 찾고 직접적으로 제어할 수 있다는 점에서는 장점이 있어
end-to-end 학습과 별개 모델 학습이라는 두 가지 방법론이 모두 혼재할 수 있습니다.
Datasets for Text Detection & Transcription
ICDAR, Total-Text, CTW1500 및 SynthText 등이 text detection의 대표적인 데이터셋인데
이들은 문서 내 텍스트가 아니라 장면 내 텍스트를 위주로 다루고 있습니다.
document의 detection 및 transcription 과정 학습을 위해 고안된 데이터셋으로는
FUNSD가 있으며, ICDAR 2019 챌린지에서 등장했던 영수증 데이터인 SROIE도 대표적입니다.
Step 3 : Information Extraction(IE)
영수증에서 상품 이름, 개수 및 가격 정보 등의 관계를 정확하게 추출하는 등의 과정은
단순히 텍스트를 가져오는 것 이상의 지식을 모델에 가르치는 과정이 필요합니다.
페이지 레이아웃과 텍스트에 담긴 의미 등을 통하여 최종적으로 원하는 지식의 형태를
가져오는 IE 과정을 위하여 다음과 같은 접근법들이 있었습니다.
2D Positional Embeddings
텍스트의 개체 종류(장소, 인명, 개수 등)를 파악하는 NER과 bounding box 사이의
상대적 위치를 고려하는 것은 텍스트 간 정보 관계 파악에 큰 도움이 될 수 있습니다.
상대적 위치를 고려하기 위하여 x, y축의 차이를 고려하는 2D 위치 임베딩과
sin, cos 함수를 활용한 위치 임베딩이 모두 고려되었으며,
텍스트마다 line number를 예측하여 할당하려는 시도도 있었습니다.
위와 같은 시도들에서 큰 성과가 있기는 하였으나, 구부러진 텍스트나 고르지 않은 표면 등의
상황과 로고 이미지 등 중요 정보를 놓치는 문제를 해결할 필요가 남아있습니다.
이를 해결하기 위하여 Faster R-CNN에서 detection된 이미지 부분을 활용하여
실제 이미지 내에서의 2D 위치 임베딩을 시도한 사례가 있었습니다.
Image Embeddings
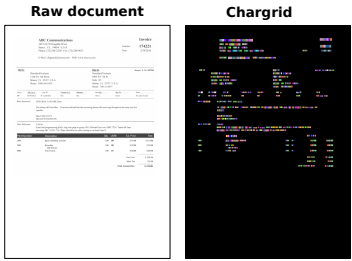
위 Figure처럼 문서 이미지를 텍스트 위치에 해당하는 텍스트들을 임베딩한 결과로
통째로 인코딩할 수 있게 학습하는 시도가 있었습니다.
이러한 방법은 2D 상의 위치를 그대로 활용할 수 있다는 장점이 있으며,
문서 임베딩을 활용하여 컴퓨터 비전 문제로 OCR 및 IE 문제를 풀 시도를 할 수 있습니다.
참고로, 이 때 output의 차원은 W(너비) * H(높이) * D(임베딩 차원)이 됩니다.
문서 이미지 임베딩 시도로는
1) character 단위를 인코딩하는 CharGrid
2) Word2Vec이나 FastText에서의 word 단위를 임베딩을 활용하는 WordGrid
3) word를 BERT에 인코딩한 결과를 활용하는 BERTGrid
4) context-specific한 character vector를 활용하는 C+BERTGrid
등이 있었으며,
이 중 C+BERTGrid가 가장 좋은 성능을 기록했었습니다.
이 외에도 grid를 두고 각 token 임베딩을 고유한 grid에 매핑시켜 텍스트 임베딩 정보 및
2D 공간 관계 활용이라는 점은 유지하며 이미지 임베딩의 차원을 줄인 시도도 있었습니다.
Documents as Graphs
문서 내의 각 텍스트 부분들을 node로 간주하고 텍스트 간의 관계를 edge로 표현하는
그래프로 문서 이미지를 해석할 수도 있습니다.
BiLSTM 같은 인코더로 문서 내 텍스트를 node로 만들 수 있으며,
이 때 edge는 binary adjacency matrix 혹은 richer matrix로 표현이 가능합니다.
이후 graph convolutional network에서 다른 종류의 receptive fields를 적용하여
local 및 global 정보를 모두 배울 수 있게 하며, 학습된 표현은 tagging decoder에 넘겨집니다.
edge가 나타내는 정보의 유형으로는 2가지가 제안되었는데 이는 다음과 같습니다.
1. STORENAME → Peet’s → Coffee처럼 동일 카테고리 기준 segment 표현
2. Peet’s → 94107(우편번호)처럼 다른 그룹 사이 연결 관계 표현
Tables
문서 내에는 스프레드시트 표 형태로 지식이 저장된 경우도 많기에
표 자체를 인식하려는 방식으로도 정보 추출을 해볼 수 있습니다.
다만, 표 전체에 대한 bounding box뿐 아니라 각 셀에 해당하는 부분도 정확하게
나누어주어야 한다는 것이 중요한 점입니다.
이를 위하여 제안된 3단계의 방법으로 cell featurization -> object detection ->
uncertainty-based active learning sampling
으로 표 단위 인식을 진행하려 시도한 사례가 있었습니다.
이 방법은 YOLO-v3, Mask R-CNN와 같은 전통적인 컴퓨터 비전 방법론들보다
더 뛰어난 table detection 성능을 보여주었습니다.
다만, 이 방법이 일반적인 스프레드시트에 대하여 모두 좋은 성능을 보인 것은 아니었는데,
table regions, structural components of spreadsheets, and cell types 등의 정보를
같이 곁들여 학습할 수 있는 multitask framework로 돌파구를 찾으려 했었습니다.
마지막으로 TUTA라는 트랜스포머 기반 table 이해 모델이 제시되었는데,
token, cell, and table level 모두에서 table이 잘 이해되도록 pretrain 방법이 고안되었고
cell type 분류를 위한 다양한 데이터셋에 fine-tune되었을 때 좋은 성능을 보였습니다.
'인공지능 논문정리 > Vision 논문' 카테고리의 다른 글
| [논문 요약] Vision Transformer(ViT) 주요 특징 정리 (0) | 2022.07.26 |
|---|---|
| [술술 읽히는 논문 요약] Supervised Contrastive Learning (0) | 2021.10.31 |
| [술술 읽히는 논문 요약] FaceNet 논문 - Triplet loss (3) | 2021.10.31 |