비전 트랜스포머 특징 요약
NLP에서 주로 사용되던 트랜스포머 구조를 비전 도메인에 적용하여
vision AI 분야의 판도를 뒤바꾼 vision transformer(ViT)를 소개했던
논문을 바탕으로 ViT에 대한 주요 특징들에 대하여 간단히 정리해보도록 하겠습니다.
논문의 제목은
"An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale"
이며, ICLR 2021에 등재된 paper입니다.
CNN vs Transformer
ResNet을 비롯한 CNN 구조의 모델들은 이미지 위상 정보를 학습에 반영하기
용이하다는 점을 바탕으로 vision 도메인에서 우위를 점하고 있었습니다.
반면, BERT와 같은 transformer 구조의 모델들은 큰 구조의 모델을
큰 데이터셋을 통하여 pre-train하는 방식으로 언어의 복잡한 내재된 정보 학습을
용이하게 만들고, token sequence에 대하여 positional embedding, attention matrix
등을 활용하여 단어 순서와 관계 정보를 학습에 반영하기 좋게 만들어
NLP 도메인에서 우위를 점하고 있습니다.
그렇다면 vision 도메인에서 transformer 구조의 장점들을 활용하여 고성능을 나타내는
모델 구조와 학습 방법을 고안해낼 수 있을까요?
해당 논문에서는 이 질문에 완벽한 대답을 해주는데 이에 대한 내용 요약을
이해하기 쉽게 간략히 설명해보도록 하겠습니다.
Vision Transformer(ViT) 구조, 학습 방법

Patch token 생성
이미지를 문장 내 단어 토큰들처럼 단위를 쪼개기 위해서
P * P 사이즈의 Patch 여러 조각으로 쪼개어 토큰으로 활용하는 방법을 제안합니다.
예를 들어, 64 * 64 픽셀의 이미지를 16 * 16 크기의 패치로 쪼갠다면 x/y축 방향마다 4칸씩
총 16개의 패치로 구성되어 64 토큰 길이를 가지는 문장처럼 다루는 것입니다.
이후, 각 Patch는 linear projection layer를 거친 뒤, flatten된 벡터 형태인
토큰 임베딩으로 전환되어 transformer 구조의 최종 input으로 활용하게 됩니다.
Positional Embedding
NLP 도메인의 transformer 구조에서 문장의 몇 번째 위치 토큰인지를 알려주는
positional embedding과 유사하게
비전 도메인에서도 Patch에서 생성된 최종 토큰 임베딩에 각 패치의
이미지 내에서의 위치를 알려주는 값을 더해주는 과정이 필요합니다.
이미지의 위상은 문장 내 토큰 순서와는 다르게 2차원이라는 특징을 가지고 있지만,
실험 결과 2D임을 명시한 위치 임베딩이 뛰어난 성능을 보이지는 않아
NLP에서와 유사한 1D learnable positional embedding 구조를 최종 채택했습니다.
Encoder 구조만 활용
최종 생성된 patch + position 임베딩 벡터 구조를 input으로 받아
transformer encoder 구조에 순서대로 입력해줍니다.
다만, 여기서는 문장 생성처럼 순차적 생성 과정이 필요한 것은 아니기에
기존 decoder 구조는 활용하지 않고 인코딩 결과에 MLP layer를 달아
최종 분류 결과를 출력하는 식으로 설계하였습니다.
Pre-train -> Fine-tune
NLP에서 큰 데이터셋을 활용한 pre-train이 고성능에 필수 조건인 것처럼
해당 논문에서도 pre-train 데이터셋의 크기를 강조하기 위하여
ImageNet(약 130만 장), ImageNet-21k(약 1400만 장) 및 JFT(약 3억 장)의 셋으로
각각 pre-train을 한 뒤, CIFAR-10/100처럼 다른 데이터셋에 대하여 fine-tune을
진행한 결과를 비교하였습니다.
이 외의 특징
- CNN 구조에 비하여 위치 정보에 대한 inductive bias가 상대적으로 작다는 특징
(self-attention에서 위치 관계를 global하게 배웁니다.)
- 패치의 크기가 작아지면 전체 패치 토큰의 수는 quadratic하게 증가하는 특징
- fine-tune 과정에서 pre-train 때 사용한 이미지보다 더 높은 해상도를 가지는 이미지를
사용하려는 경우 2D interpolation을 통한 패치 토큰 수를 맞춰줄 수 있다는 특징
등이 Vision Transformer의 추가적인 중요한 특징들입니다.
결과 분석
BERT-base, BERT-large 등 다양한 버전 크기의 트랜스포머 모델이 존재하는 것처럼
ViT도 3가지 다른 크기 버전의 모델을 논문에서 제안하고 있었습니다.
참고로, ViT-large는 BERT-large(약 345M)에 가까운 파라미터 수를 보유하고 있으며,
patch의 크기에 따라 같은 크기 파라미터 모델도 다른 버전이 존재할 수 있으므로,
ViT-L/16(patch size 16인 large 모델)처럼 notation을 정해두고 있습니다.
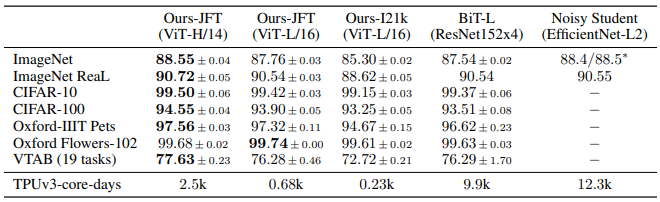
위 Table 2의 첫 두 column의 결과는 파라미터 수의 영향을 보여주고 있으며,
두 번째와 세 번째 column의 결과 사이는 pre-train 데이터셋 크기의 영향을
나타내고 있었습니다.
파라미터 수 및 pre-train 데이터셋 크기는 NLP 트랜스포머처럼 성능에 아주 중요한
영향을 끼치고 있었으며, baseline으로 삼은 BiT(ResNet을 의미합니다.)보다
실험한 모든 데이터셋에서 대하여 높은 성능을 보이고 있음을 확인할 수 있었고,
기존에 강력한 성능을 보였던 semi-supervised learning 기반 학습된
EfficientNet에도 견줄 수 있는 성능을 기록하였습니다.
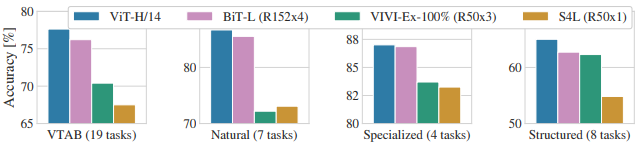
총 19개의 task에 대하여 각 task 당 단 1000개의 이미지로만 구성된
low-data transfer의 성능을 측정할 수 있는 VTAB에 대하여 실험한 결과도
ViT에서 다른 baseline을 압도하는 성능을 기록한 점을 확인 가능했습니다.
'인공지능 논문정리 > Vision 논문' 카테고리의 다른 글
| [논문 요약] A Survey of Deep Learning Approaches for OCR and Document Understanding (0) | 2022.07.31 |
|---|---|
| [술술 읽히는 논문 요약] Supervised Contrastive Learning (0) | 2021.10.31 |
| [술술 읽히는 논문 요약] FaceNet 논문 - Triplet loss (3) | 2021.10.31 |