Python torch data parallelism 사용법
파이토치에서 데이터 병렬 처리를 적용하는 방법에 대한 예제를 살펴보도록 하겠습니다.
해당 글은 아래 링크의 파이토치 공식 사이트의 글을 기반으로 작성되었으며,
좀 더 자세한 설명이 필요하시다면 해당 글을 참고해주세요.
선택 사항: 데이터 병렬 처리 (Data Parallelism)
글쓴이: Sung Kim and Jenny Kang 번역: ‘정아진 < https://github.com/ajin-jng>’ 이 튜토리얼에서는 DataParallel(데이터 병렬) 을 사용하여 여러 GPU를 사용하는 법을 배우겠습니다. PyTorch를 통해 GPU를 사용하는
tutorials.pytorch.kr
상황 가정
우선, 아래와 같이 파라미터 수가 많은 네트워크를 하나 가정해보도록 하겠습니다.
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(20000, 10000)
self.fc2 = nn.Linear(10000, 5000)
self.fc3 = nn.Linear(5000, 1)
def forward(self, x):
return self.fc3(self.fc2(self.fc1(x)))
디바이스 및 데이터셋 설정 과정은 아래와 같이 설정하여 보겠습니다.
from torch.utils.data import TensorDataset, DataLoader
import numpy as np
# 디바이스 지정(GPU가 여러개 있는 상황을 가정)
device = torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu')
# 데이터셋 가정
X = torch.tensor(np.random.random((600, 20000))).float().to(device)
y = torch.tensor(np.random.random(600)).float().to(device)
dataset = TensorDataset(X, y)
dataloader = DataLoader(dataset, batch_size = 6)
위에서 선언한 Net() 구조를 model 변수에 지정한 뒤에
아래와 같은 가상의 학습 코드를 실행하는 상황을 가정해보도록 하겠습니다.
epochs = 10000
loss_function = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
for i in range(epochs):
for X, y in dataloader:
y_pred = model(X)
loss = loss_function(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
이제 데이터 병렬 처리를 적용한 경우와 그렇지 않는 경우에 대한
model 변수 선언 코드와 실행 결과 차이를 살펴보도록 하겠습니다.
GPU 1개만 사용하려는 경우
모델 변수 선언 시 to(device)로만 단순히 지정해준다면
기본적으로 가장 앞 번호의 1개의 GPU만 사용하게 됩니다.
model = Net().to(device)
nvidia-smi로 사용 중인 GPU 현황을 살펴보면 아래처럼 1개만 사용 중인 상황으로 나옵니다.
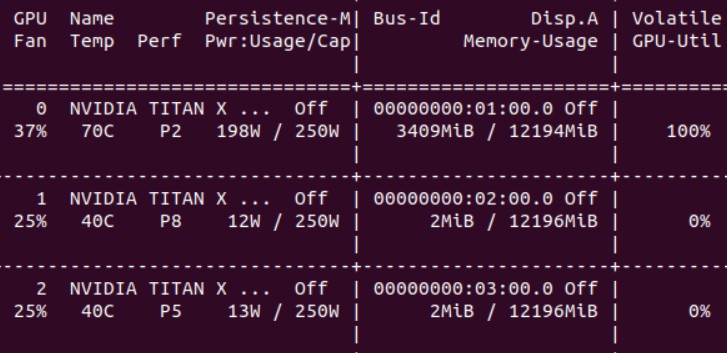
모든 GPU를 사용하여 데이터 병렬 처리를 하려는 경우
만일, 보유 중인 GPU 전부를 사용하고 싶다면, nn.DataParallel 메소드를 활용하여
아래와 같이 model 변수를 지정해주시면 됩니다.
(참고 : 이 경우도 마지막에 to(device)를 반드시 포함시켜 주셔야 합니다.)
model = Net()
model = nn.DataParallel(model).to(device)
GPU 사용 현황 조회 결과, 모든 GPU에 데이터 병렬 처리가 적용된 점을 살펴볼 수 있었습니다.
(참고 : GPU 당 메모리 사용량이 줄어들지는 않았지만 속도 향상 기대가 가능합니다.)

일부 GPU 번호를 지정하여 데이터 병렬 처리를 하려는 경우
모든 GPU 전부는 아니지만 원하는 GPU의 번호 들을 지정하여
여러 개의 GPU에 대한 데이터 병렬 처리를 하려는 경우는 nn.DataParallel 메소드 내의
device_ids 인자에 원하는 GPU 번호 리스트를 지정해주시면 됩니다.
model = Net()
model = nn.DataParallel(model, device_ids = [0, 1]).to(device)
사용 현황을 살펴보면 2번 GPU는 제외하고 0과 1번 GPU에만 데이터 병렬 처리가
진행된 것을 살펴볼 수 있었습니다.

'Python > Pytorch' 카테고리의 다른 글
| [Pytorch] 체크포인트(checkpoint) 설명, 저장 및 불러오기 예제(epoch별, step별, best) (0) | 2022.07.18 |
|---|---|
| [Pytorch] 모델에 저장된 파라미터 확인, 출력 방법 (0) | 2022.05.13 |
| [Pytorch] DataLoader의 기능과 사용법 정리 (0) | 2022.05.10 |