파이썬 파이토치 DataLoader 이해하기
파이토치 모듈에서 모델 학습 과정 시 각 step 마다 데이터를 batch size 크기로 분할하여 넣어
효과적이고 효율적인 학습 진행을 돕는 dataloader의 기능을 이해해보고
사용법 예시 코드를 쉽고 간략하게 정리해보도록 하겠습니다.
DataLoader의 기능, 사용 이유
이해를 돕기 위하여 x, y 두 벡터를 input으로 받는 모델을 학습하려는 상황을 가정해보겠습니다.
그리고 아래와 같이 1000개의 데이터가 있다고 생각해보도록 하겠습니다.
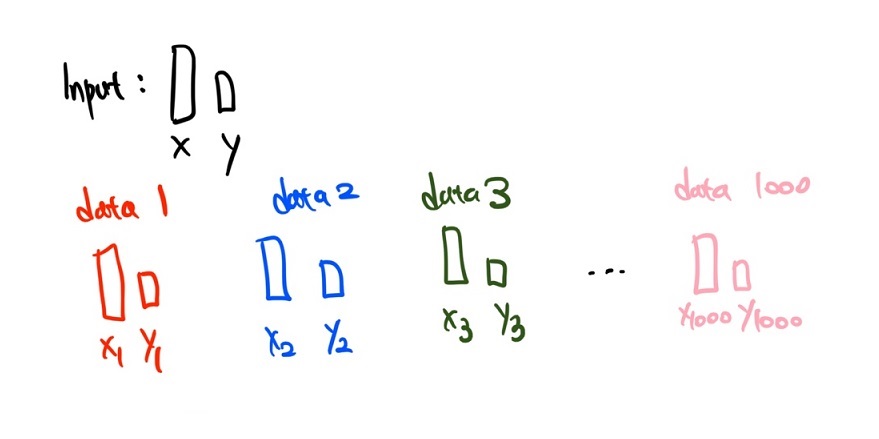
# 다음과 같은 형태로 데이터가 존재한다고 가정
data = [[x1, y1], [x2, y2], [x3, y3], ... , [x1000, y1000]]
이제 이 데이터를 통하여 모델을 학습하려면 어떤 형태로 넣어줘야 할까요?
여러 가지 방법이 있는데 아래와 같이 데이터를 1개씩 넣어줄 수도 있고,
x 벡터끼리, y 벡터끼리 모아서 한 번에 넣어줄 수도 있습니다.
# 데이터를 1개씩 넣는 방법
for d in data:
x = d[0]
y = d[1]
logits = model(x, y)
# 데이터 전체를 한 번에 넣는 방법
X = torch.tensor([x1, x2, x3, ... , x1000])
Y = torch.tensor([y1, y2, y3, ... , y1000])
logits = model(X, Y)
그러나, 위의 두 방법은 모두 각각의 단점이 존재합니다.
데이터를 1개씩 넣는 방법은 시간이 매우 오래걸리고
컴퓨터 자원(GPU 등)을 효율적으로 사용할 수 없습니다.
반면, 데이터 전체를 한 번에 넣는 방법은 데이터가 조금이라도 클 경우
컴퓨터 자원이 데이터를 감당할 수 없게 됩니다.
따라서, 모델에 데이터를 넣어주기 전, 적당한 양씩 데이터를 나누는 과정이 필요하게 되고
dataloader에서 이 과정을 수월하게 만들어주는 기능을 하므로 사용하는 것입니다.
DataLoader 사용 과정, 코드 예제
Step 1. dataset 생성
pytorch의 dataloader를 사용하기 위해서는 우선 필요한 input 벡터들이 적절히 묶인
형태로 데이터 셋을 만들어주어야 합니다.
이 과정에는 zip 함수를 사용해도 되고,
파이토치에서 제공하는 TensorDataset 함수를 사용해도 좋습니다.
import torch
from torch.utils.data import TensorDataset
X = torch.tensor([x1, x2, x3, ... , x1000])
Y = torch.tensor([y1, y2, y3, ... , y1000])
dataset = list(zip(X, Y)) # zip 함수 사용 예시
dataset = TensorDataset(X, Y) # TensorDataset 함수 사용 예시
Step 2. DataLoader 함수 설정
이후, DataLoader 함수에서 위에서 묶은 데이터 셋을 분할해줄 준비를 해주면 됩니다.
여러 가지 옵션을 지정할 수 있지만, 여기서는 1 step에 넣어줄 데이터의 개수를 정하는
batch_size 옵션과 순서를 섞어서 분할할지 여부를 정하는 shuffle 옵션을 지정해보겠습니다.
from torch.utils.data import DataLoader
dataloader = DataLoader(
dataset, # 위에서 생성한 데이터 셋
batch_size = 32, # 1회 당 32개의 데이터씩 분할
shuffle = True # 데이터들의 순서는 섞어서 분할
)
Step 3. 순회를 통해 분할된 데이터 가져와 사용
DataLoader 객체는 일종의 generator 형태로, 인덱싱이 불가능하고
for문 순회 등의 방법을 통하여 분할된 데이터를 일일이 가져와야 합니다.
예시로, 아래처럼 코드를 작성하여 batch 단위의 데이터를 가져와 학습에 사용할 수 있습니다.
for batch in dataloader:
batch_x = batch[0] # 분할된 32개의 x 벡터 모음
batch_y = batch[1] # 분할된 32개의 y 벡터 모음(x 벡터와 pair 순서 일치)
logits = model(batch_x, batch_y)'Python > Pytorch' 카테고리의 다른 글
| [Pytorch] 모델에 저장된 파라미터 확인, 출력 방법 (0) | 2022.05.13 |
|---|---|
| [Pytorch] GPU 여부 확인, 사용할 GPU 번호 지정, 모델 및 텐서에 GPU 할당 방법 (4) | 2022.04.24 |
| [Pytorch] 파이토치 특정 layer freeze 방법 (0) | 2022.04.22 |