파이썬 파이토치 체크포인트 사용법
python torch 모듈에서 학습된 모델의 저장 및 불러오기 과정에서 자주 보이는
체크포인트(checkpoint) 개념에 대하여 정리해보고
epoch별, step별, best 등의 체크포인트를 직접 지정하여 저장 및 불러오기를
해보는 예시를 다루어보겠습니다.
파이토치에서 체크포인트란?
파이토치의 checkpoint는 학습 중인 모델의 특정 시점의 상태를 보존하여 저장했다가
그대로 불러와 이어서 학습하거나 혹은 evaluation을 수행할 수 있게 해주는 파일을 의미합니다.
사실, 체크포인트라는 말은 따로 용어가 있다고 하기보다는
아래 글의 모델의 저장 및 불러오기 과정과 거의 일치한다고 보셔도 됩니다.
[Pytorch] 파이토치 모델 저장, 불러오기 방법
torch model save, load 예제 이번 글에서는 파이토치에서 학습된 모델을 저장하고, 저장된 모델을 다시 불러오는 방법을 파라미터만 저장하는 방법과 모델 전체를 save하는 방법으로 나누어서 설명해
jimmy-ai.tistory.com
모델 저장/불러오기의 구조는 단일 모델 파일만 저장해도 좋고 여러 정보를 딕셔너리 형태로 모아
저장하는 것도 가능한데, 상세한 예제가 궁금하시다면 아래의 파이토치 공식 글을 참고해주세요.
모델 저장하기 & 불러오기
Author: Matthew Inkawhich, 번역: 박정환,. 이 문서에서는 PyTorch 모델을 저장하고 불러오는 다양한 방법을 제공합니다. 이 문서 전체를 다 읽는 것도 좋은 방법이지만, 필요한 사용 예의 코드만 참고하
tutorials.pytorch.kr
상황 가정
우선, 다음과 같이 아주 간단한 구조의 신경망으로 학습하고 싶은 모델을 가정해보겠습니다.
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(8, 4)
self.fc2 = nn.Linear(4, 2)
self.fc3 = nn.Linear(2, 1)
def forward(self, x):
return self.fc3(self.fc2(self.fc1(x)))
위의 모델에서 사용될 데이터셋은 아래와 같이 가정해보았으며,
0과 1 중에서 라벨을 구분하는 분류 task를 가정해보도록 하겠습니다.
from torch.utils.data import TensorDataset, DataLoader
import numpy as np
# 데이터셋 가정(1600개 데이터)
X = torch.tensor(np.random.random((1600, 8))).float() # 8차원으로 구성된 1600개 데이터
y = torch.tensor(np.random.randint(2, size = (1600, 1))).float() # 0 또는 1의 라벨
dataset = TensorDataset(X, y)
dataloader = DataLoader(dataset, batch_size = 16) # 총 100개의 배치로 구성
모델 선언 및 loss 함수, optimizer 구성, 기본적인 train 코드는 아래와 같이
작성된 상황을 가정해보고, 이제 상황별로 체크포인트를 직접 저장해보도록 하겠습니다.
(현재 코드의 train 코드 파트에서 바뀌는 부분을 주목해주시면 됩니다.)
# 모델 선언
model = Net()
# loss 함수 및 optimizer 선언
loss_function = nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
# train 코드 예시
epochs = 10
model.train()
for i in range(epochs):
for X, y in dataloader:
y_pred = model(X)
loss = loss_function(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch별로 체크포인트를 저장하려는 경우
대표적인 체크포인트 저장 방법으로
한 epoch가 종료될 때마다 모델 파일을 저장하는 예시를 살펴보겠습니다.
for i in range(1, epochs + 1):
for X, y in dataloader:
y_pred = model(X)
loss = loss_function(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
torch.save(model, 'checkpoint/checkpoint_ep_%d.pt'%i) # 각 epoch가 끝날 때마다 모델 상태 저장torch.save 함수의 두 번째 인자 부분의 디렉토리 부분은 원하시는대로 작성해주시면 됩니다.
(단, epoch 마다 파일명이 구분되게 해주셔야 합니다.)
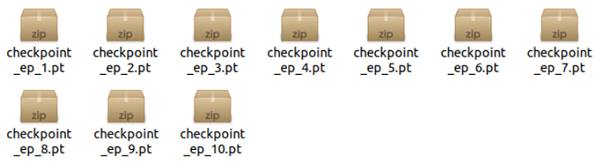
위 코드 실행 후 checkpoint 폴더에 들어가보면 다음과 같이
모델 파일들이 잘 저장된 것을 보실 수 있습니다.
만일, 딕셔너리 형태로 모델의 여러 정보를 같이 포함하여 체크포인트로 남기고 싶다면
아래 코드과 같이 작성해주시면 됩니다.
for i in range(1, epochs+1):
for X, y in dataloader:
y_pred = model(X)
loss = loss_function(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
torch.save({'epochs' : epochs+1,
'model' : model.state_dict(),
'optimizer' : optimizer.state_dict(),
}, 'checkpoint/checkpoint_ep_%d.pt'%i)
step별로 체크포인트를 저장하려는 경우
만일, 데이터셋의 용량 혹은 모델의 파라미터 수가 매우 크다면 1 epoch도 버거워
중간 특정 step 수 경과 시점에서 체크포인트를 만드는 것이 필요한 경우가 있습니다.
위의 가정에서는 한 epoch가 배치의 개수인 100 스텝으로 구성되어있는데,
2 epoch까지 20 스텝 단위로 모델을 저장하는 예시 코드를 작성해보겠습니다.
epochs = 2
for i in range(1, epochs+1):
for step, (X, y) in enumerate(dataloader): # enumerate로 step 수 카운팅
y_pred = model(X)
loss = loss_function(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 중간 특정 스텝 수 달성 시마다 저장
if step % 20 == 19:
torch.save(model, 'checkpoint/checkpoint_ep_%d_step_%d.pt'%(i, step+1))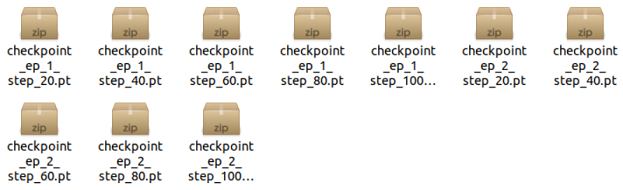
best evaluation 시점의 체크포인트를 저장하려는 경우
epoch가 종료되는 시점에서 evaluation을 진행한 뒤,
가장 evaluation 성능이 좋았던 지점의 체크포인트를 저장하려는 경우가 있습니다.
이럴 때에는 다음과 같이 epoch 종료 후 모델 평가 수행 후 기존 최고 성능보다 개선된 경우에만
모델 파일을 갱신해주시면 됩니다.(같은 이름으로 다시 저장 시 자동으로 덮어쓰기됩니다.)
epochs = 10
min_eval_loss = 99999999 # loss 갱신 여부 탐색하기 위한 변수
# 성능 평가용 데이터셋 가정(64개 데이터)
X_eval = torch.tensor(np.random.random((64, 8))).float() # 8차원으로 구성된 64개 데이터
y_eval = torch.tensor(np.random.randint(2, size = (64, 1))).float() # 0 또는 1의 라벨
dataset_eval = TensorDataset(X_eval, y_eval)
dataloader_eval = DataLoader(dataset, batch_size = 16) # 총 4개의 배치로 구성
for i in range(1, epochs+1):
model.train() # 학습 모드 전환
# 해당 epoch 학습
for X, y in dataloader:
y_pred = model(X)
loss = loss_function(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval() # 평가 모드 전환
# 성능 평가 진행
eval_loss = 0
for X, y in dataloader_eval:
y_pred = model(X)
eval_loss = loss_function(y_pred, y)
print('epoch :',epochs, ', eval_loss :', eval_loss)
# 갱신된 경우 체크포인트 파일 저장(loss 값을 기준으로 삼은 예시)
if eval_loss < min_eval_loss:
min_eval_loss = eval_loss
torch.save(model, 'checkpoint/checkpoint_best.pt')
저장된 체크포인트 불러오기 방법
저장된 체크포인트를 불러오는 방법은 모델 직접 저장, 딕셔너리 형태 저장
모두 torch.load 함수로 수행해주시면 됩니다.
두 저장 형태에 따른 불러오기 방법 예시 코드는 아래와 같습니다.
# 모델 직접 저장 예시
model = torch.load('checkpoint/checkpoint_file_name.pt')
# 딕셔너리 형태 저장 예시
checkpoint = torch.load('checkpoint/checkpoint_file_name.pt')
model = Net() # 모델 구조 생성
model.load_state_dict(checkpoint['model']) # state_dict 형태로 저장된 파라미터 불러오기
'Python > Pytorch' 카테고리의 다른 글
| [Pytorch] 파이썬 Contrastive Learning 구현 예제(feat. SimCLR) (2) | 2022.07.20 |
|---|---|
| [Pytorch] 파이썬 파이토치 데이터 병렬 처리 적용 예제 : nn.DataParallel (0) | 2022.07.14 |
| [Pytorch] 모델에 저장된 파라미터 확인, 출력 방법 (0) | 2022.05.13 |