REALM Paper Review
이번 글에서는 Open-Domain QA(ODQA) 분야에 한 획을 그었던 REALM 논문에서 설명했던
기법을 간략하게 요약하여 다루어보도록 하겠습니다.
참고로, 해당 논문의 제목은
"REALM: Retrieval-Augmented Language Model Pre-Training"이며,
ICML 2020 학회에 등재되었던 paper입니다.
실험 배경
트랜스포머 기반 언어 모델의 pre-train 과정은 성능에 있어 매우 중요하다는 것이 밝혀졌으며,
이 pre-train하는 과정에서는 지식들이 implicit한 방식으로 파라미터 내에 저장됩니다.
그러나 만일 언어 모델이 explicit하게 관련된 지식들을 먼저 찾을 수 있게 학습한 뒤,
해당 관련 지식을 참조하여 최종 output을 생성하게 된다면
어떤 지식을 참조했는지의 정보를 살펴볼 수 있기에 결과 해석이 용이해질 수 있습니다.
ODQA task에서는 질문에 대한 관련 문단들을 먼저 찾는 Retrieval 부와
해당 문단들에서 답변을 찾는 Reader 부의 구조로 이루어진 프레임워크가 강세를 보이고 있는데,
REALM 논문에서는 ODQA 모델을 학습시키기 전에
Retrieval-Reader 특징을 활용한 pre-train을 진행한 뒤, 본학습을 수행하면
ODQA의 성능을 향상시킬 수 있지 않을까하는 기대에서 출발을 하게 되었던 것입니다.
REALM 프레임워크 설명

우선, REALM 모델도 기본적으로는 다른 ODQA 모델처럼 Retrieval-Reader의 두 모델로
이루어져 있습니다.(위 그림의 파란색 부분 2개)
트랜스포머 기반 구조 모델을 pre-train하는 과정은 주로 mask prediction으로 진행되는데,
REALM에서는 해당 pre-train 과정을 차용하여
mask가 포함된 해당 문장과 관련이 있는 document를 찾는 식으로 Retrieval의 pre-train이,
기존 문장 + 찾은 문서를 concat한 결과에서 최종 mask의 토큰을 예측하는 방식으로
Reader의 pre-train이 이루어지는 형태의 학습을 진행하였습니다.
위 과정으로 pre-train이 진행된 REALM ODQA 모델에 대하여
fine-tune 과정은 다른 ODQA 모델과 같이 Retrieval에서는 질문에 대한 관련 문서를 찾고,
Reader에서는 해당 문서들에서 답변 위치의 span을 찾는 식으로 진행됩니다.
즉, pre-train과 fine-tune 과정의 차이는 input과 output 형태가
mask prediction이냐 아니면 question answering이냐의 차이로 볼 수 있으며,
약간 다른 형태로 Retrieval-Reader 프레임워크 학습이 2회 진행되는 것으로 보시면 됩니다.
Training Technic
Asynchronous MIPS Refresh
Retrieval에서는 수많은 문서(1~2천만개 가량) 중에서 관련 문서를 찾아야하기에
문서의 인코딩 결과를 미리 저장해두고, 질문의 인코딩 결과가 들어왔을 때,
내적 값들을 빠르게 계산하여 가장 가까운 top-k 벡터를 찾는 MIPS라는 방식이 사용됩니다.
그러나, 모델의 파라미터가 업데이트될 때마다 저장된 인코딩 결과를 refresh해주려면
지나치게 많은 시간이 소요될 수 있고,
업데이트를 너무 진행하지 않게되면 out-of-date의 인코딩 결과를 참조하는 셈으로
성능이 크게 하락할 수 있어,
특정 스텝 수(이 실험에서는 매 500스텝)마다 해당 시점의 파라미터를
기준으로 저장된 인코딩 결과를 업데이트하는 Asynchronous MIPS refresh 방식을
적용하였고, 성능과 시간의 trade-off의 최적점을 찾아내었다고 볼 수 있습니다.
What does the retriever learn?
주황색 식은 질문 x에 대한 답변 y의 확률이므로 증가하는 방향으로 학습이 진행되는데,
만일 찾은 문서인 z가 답변 y를 찾는데에 도움이 되었다면 r(z)는 양수가 되고,
z가 없는 경우의 기대값보다도 낮게 되면 r(z)는 음수가 됩니다.
여기서 relevance score 부분이 r(z)가 양수일 때는 커져야 왼쪽 식이 커지고,
반대로 음수인 경우는 작아져야 왼쪽 식이 증가하게 되므로,
relevance score 부분은 찾은 문서가 답변 탐색에 도움이 되었는지를 알려주는 r(z) 값의
부호에 따라 학습 방향이 결정되어, 직관적으로 Retrieval 학습이 이루어짐을 알 수 있습니다.
기타 테크닉
Salient Span Masking : ‘United Kingdom’, ‘July 1969’처럼 여러 단어로 구성된 말뭉치를
통째로 masking하여 pre-train 과정에 반영하였습니다.
Null Document : pre-train 과정에서 Reader 부에서 mask를 예측할 때, top-k 문서 외에도
빈 문서를 추가로 넣어 mask 문장 내에서 mask 예측이 바로 가능한 경우를 고려하였습니다.
Prohibiting Trivial Retrievals : 찾은 문서와 mask 문장의 단어들이 거의 완벽하게 일치하는
경우에 cheating을 방지하게 하기 위하여 이런 경우를 미리 제거하였습니다.
Initialization : Inverse Cloze Task(ICT)라는 문맥 중간의 문장을 보고 어떤 문맥에서 등장한
문장인지를 예측하는 task로 학습 과정 내 cold-start 문제를 방지하였습니다.
결과 분석
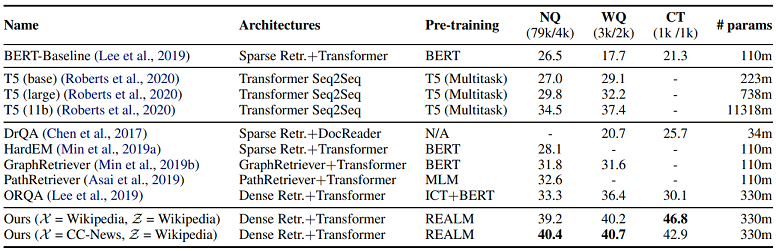
NaturalQuestions(NQ), WebQuestions(WQ) 및 CuratedTrec(CT)의 세 가지 벤치마크
ODQA 데이터셋에 대하여 Exact Match 성능 비교를 진행하였습니다.
실험 결과, 330m 파라미터 사이즈로 모든 벤치마크에 대하여 기존 기법들을 뛰어넘는
최고성능(SOTA)를 기록하였으며,
특히 pre-train 시 mask 문장이 추출된 코퍼스(X)와 검색될 문맥을 추출할 코퍼스(Z)를
다른 종류의 코퍼스로 둔 경우 NQ 및 WQ에서 약간의 성능 향상이 있었습니다.
이는 corpus 종류에 따른 generalization이 잘 되었음을 의미하기도 합니다.

pre-train만 완료된 Retrieval도 top-5 문서 내에서 답변이 자주 등장하는 사실을 확인했으며,
Salient Span Masking은 성능 향상에 큰 도움을 준다는 사실을 입증하였습니다.
또한, 500 스텝 대신 15000 스텝마다 MIPS 인덱스를 업데이트하는 것은
성능을 큰 폭으로 떨어뜨린다는 사실을 확인하였습니다.

위의 Table 3의 예시에서는 BERT에서는 거의 예측하기 어려웠던 mask 토큰을
REALM에서 mask 문장(x)만 주어졌을 때도 어느 정도 높은 확률(0.129)로 예측을 하고 있었고,
특히 관련 문단(z) 정보까지 준 경우에는 거의 확실한 확률(1.0)로 예측을 할 수 있던 예시를
보여주고 있습니다.