Fusion-in-Decoder Paper Review
이번 글에서는 Open Domain QA 분야에서 강력한 성능을 보이는 Reader 구조인
Fusion-in-Decoder(FiD) 모델에 대한 논문의 내용을 요약해보도록 하겠습니다.
논문의 제목은 Leveraging Passage Retrieval with Generative Models for
Open Domain Question Answering이며, EACL 2021 학회에 등재된 페이퍼입니다.
실험 배경
수 많은 문단 중 질문과 관련된 문단을 먼저 탐색하고, 여기서 답변을 찾아야 하는
Open Domain QA(ODQA) 분야에서 문단 탐색(Retrieval)-찾은 문단에서 답변 탐색(Reader)
의 2단계 구조로 이루어진 모델 들이 강력한 성능을 보였었습니다.
Reader 모델 구조의 역사를 살펴보면 이전에는 문단 내에서 정답이 되는 답변의
위치 span을 찾는 방법이 대세였다면,
현재는 답변을 직접 generate하는 생성 모델 구조가 높은 성능을 보이고 있었습니다.

이 논문에서는 생성 모델 구조의 장점을 살릴 수 있는 방법으로
이전처럼 Retrieval에서 찾은 top-k passage 각각을 따로 고려하여 답변을 찾는 것이 아니라
top-k 문단들을 전부 합쳐 디코딩 과정에서 하나의 input으로 활용하는 방법을 제안하였으며,
이러한 방법이 ODQA의 주요 벤치마크 데이터셋에 대하여 최고 성능(SOTA)를 기록하였습니다.
모델 구조, 방법론
Retrieval
관련 문서 탐색에서는 ODQA 분야의 다른 연구에서 사용되었던 방법들을 비슷하게 적용했습니다.
SQUAD 데이터셋에서는 BM25를 활용한 Sparse Retrieval의 방법론을 사용했었고,
NQ, TriviaQA 데이터셋에서는 DPR을 활용한 Dense Retrieval 방법론을 적용했었습니다.
Reader
해당 논문에서 이전 연구들과 차별화하여 실험한 부분입니다.
우선, 생성 모델의 구조로는 T5를 사용했었습니다.
상세한 구조는 위의 Figure 2처럼
Retrieval에서 추출한 모든 top-k 문단에 대하여 question과 위와 같이 이어붙여 인코더에 넣고,
인코딩된 벡터들을 concat한 벡터를 디코더에 넣어 최종 답변을 생성하는 구조였습니다.
input 토큰들의 자세한 구성은 special token인 [question:], [title:], [context:]을 두어
[question:] 질문 토큰들 [title:] passage 제목 토큰들 [context:] passage 문맥 토큰들
의 구조로 인코더에 각 문단들을 넣었습니다.
이와 같은 joint decoder를 사용할 경우 문단의 개수에 따라 시간 복잡도가
이차식이 아니라 선형으로 증가하며, 각 문단의 evidence들을 통합할 수 있게 됩니다.
데이터셋, 평가 방법, 디테일 등
데이터셋으로는 ODQA의 주요 벤치마크인 NaturalQuestions(NQ), TriviaQA 및
SQUAD 1.1 버전의 3가지 데이터셋을 사용했었습니다.
평가 방법은 생성한 답변이 답변 후보들 중에 완전히 일치하는 것이 있는지로 평가하는
Exact Match(EM)을 주로 사용했었습니다.
220M 파라미터(base)와 770M 파라미터(large)의 T5 모델에 대하여 모두 실험을 진행했으며,
탐색할 관련 문서 개수(top-k의 k)는 5, 10, 25, 50, 100으로 진행하여 결과를 비교했습니다.
결과 분석
NQ, TriviaQA 데이터셋에 대해서 base 사이즈의 T5 모델에서 조차도 SOTA를 기록했었으며,
large 사이즈의 T5 모델에서는 더 강력한 성능을 보였었습니다.
SQUAD 데이터셋에서도 large 사이즈에서는 최고 성능의 EM을 기록했었습니다.
Retrieval에서 탐색되는 passage의 개수(k)가 증가할수록 성능이 향상되는 경향이
세 가지 데이터셋 모두에서 뚜렷했었습니다.
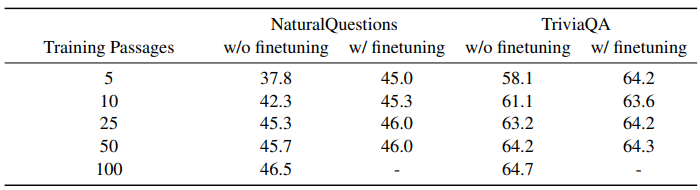
탐색 passage의 개수(k)를 낮게 설정하는 경우에 100 passages로 1000 step의 finetune만
진행해주어도 성능의 격차를 크게 줄일 수 있었습니다.
이는 컴퓨팅 자원의 효율을 크게 높이면서도 비교적 준수한 성능을 기록할 수 있음을 의미합니다.
'인공지능 논문정리 > NLP 논문' 카테고리의 다른 글
| [논문 요약] Improving language models by retrieving from trillions of tokens (0) | 2022.07.09 |
|---|---|
| [술술 읽히는 논문 요약] GloVe: Global Vectors for Word Representation (0) | 2021.11.05 |
| [술술 읽히는 논문 요약] Word2Vec 논문 - Skip-gram, CBOW (0) | 2021.11.02 |