NLP RETRO Paper Review
2022년 구글 딥마인드에서 공개된 RETRO 논문의 핵심 내용들을 요약해보도록 하겠습니다.
논문의 제목은 "Improving language models by retrieving from trillions of tokens"입니다.

실험 배경
기존의 GPT-3 등의 대규모 언어 모델(LLM)들은 지속적으로 파라미터의 수와 데이터셋의 크기를
증가시키는 방향으로 성능 향상을 도모해왔습니다.
그러나 외부의 Knowledge base(KB)의 도움을 받게된다면 비교적 적은 수의 파라미터로도
언어 모델의 성능을 크게 향상시킬 수 있다는 발상을 했었으며,
RETRO에서는 7B 정도의 파라미터로도 100B 이상의 LLM에 맞먹는 성능을 기록했었습니다.
위 Figure 1의 가장 왼쪽 그래프는 비슷한 크기의 트랜스포머 구조 baseline 언어 모델(세모)과
해당 논문에서 새롭게 제안한 RETRO 구조 언어 모델 간에서 KB에서의 Retrieval 과정이
포함되지 않는다면(x 마커) 성능에 큰 차이가 없음을 의미했으며,
Retrieval 과정 포함 시(o 마커)에는 모델 크기 대비 성능이 큰 폭으로 향상됨을 보여주었습니다.
(참고 : bits-per-byte가 낮을 수록 언어 모델 성능이 좋다고 평가하며, baseline 기준을 1.0으로
정규화하여 그래프에 표현한 듯 합니다.)
또한, Retrieval할 KB의 크기 역시 성능에 중요한 역할을 하며(두 번째 그래프),
Retrieve되는 이웃의 수는 10~30개 근처일 때 성능이 좋은 듯 했었습니다(마지막 그래프).
RETRO 모델 구조
위 Figure 2에 등장한 것 처럼 RETRO는 일반적인 트랜스포머 구조와는 약간의 차이가 있습니다.
눈여겨 볼 점은
1) 토큰 여러개가 한 묶음인 chunk 단위로 retrieval 및 attention 과정이 진행된다는 점
2) chunk attention이 진행되는 CCA라는 구조가 Decoder에 포함되어 있는데,
chunk 간 일부 overlap을 진행한 결과와 retrieval 결과 임베딩을 반영한다는 점입니다.
CCA 구조는 디코더의 일부 layer(6번째 디코딩 블록부터 3번째마다)에 포함되어 있으며,
부록에 해당 비율로 CCA와 일반 트랜스포머 디코더를 섞는 것이 가장 높은 성능을 보였다는
점이 기록되어 있었습니다.
KB 구성, Retrieval 방법
우선, RETRO에서는 training data와 Retrieval 데이터셋 모두 MassiveText를 사용했습니다.
데이터셋의 양은 약 600B 토큰이며, 다양한 데이터 소스에서 일정 비율 샘플링을 진행하여
다양한 종류의 지식을 배울 수 있게 해두었습니다.
KB의 구성은 key가 임베딩이고 value가 텍스트인 딕셔너리 형식으로 구성되어 있었는데,
key인 임베딩은 텍스트를 BERT에 넣었을 때 등장한 벡터를 사용했었습니다.
KB에서 가장 관련도가 높은 텍스트를 Retrieval할 때는 해당 텍스트의 BERT 임베딩과
L2 거리가 nearest neighbor인 k개의 key들을 이웃으로 간주했었습니다.
결과 분석
위 Figure 3처럼 4종류의 파라미터 크기로 RETRO 모델을 학습했던 결과,
일반 트랜스포머 구조처럼 파라미터 수가 클수록 성능이 좋아지는 경향이 뚜렷했었습니다.
또한, 전반적으로 Retrieval을 도입한 RETRO 구조가 baseline 대비 성능이
비슷한 파라미터 크기일 때 좋았던 점이 기록되었는데,
Wikitext103에서 차이가 많이 나는 이유는 train-test 데이터 간 overlap 때문으로
추정되었고, 이는 아래 표의 데이터셋 크기의 영향에서 뚜렷하게 나타납니다.
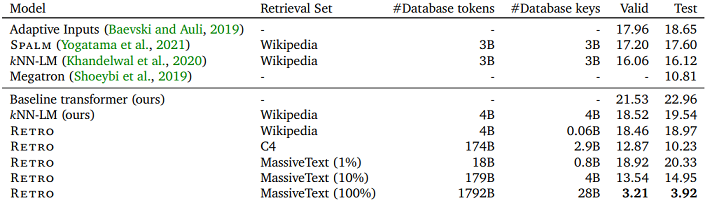
데이터셋의 용량이 커질수록 성능이 향상되는 경향은 매우 뚜렷하게 나타났었는데,
특히 4B 정도 크기의 위키피디아 문서를 사용한 경우도 knn-LM 보다 성능이 좋았던 점을
나타내어 해당 구조가 효율적인 구조임을 보여준 듯 하였습니다.
다만, MassiveText를 전부 사용한 경우에 valid 성능이 큰 폭으로 오르는 것은 위에서 언급한대로
train 데이터셋 과 데이터가 겹치는 dataset leakage 현상인 것으로 추측되었습니다.

위 Figure 4에 표현된 결과는 7B 크기의 RETRO 모델을 다양한 pile 테스트 데이터에 대하여
수백B 파라미터 크기 LLM들인 Jurassic-1, Gopher와 텍스트 생성 성능을 비교한 것입니다.
(GPT-3는 Jurassic-1, Gopher보다 대체적으로 성능이 낮아 비교를 생략했었습니다.)
0% 기준은 retrieval이 없는 baseline 7B 파라미터 크기 모델이었으며,
RETRO가 고전하는 데이터셋 종류도 있었지만 크게 압도하는 데이터셋도 있었고
전반적으로 수백B의 LLM과 비벼볼 수 있는 성능이 기록된 사실을 볼 수 있었습니다.
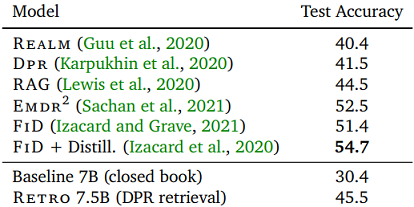
마지막으로, Retrieval을 수행하는 언어 모델 구조의 특성답게 NQ 데이터셋에 대하여
Open Domain QA(ODQA) task에서의 성능을 비교했었습니다.
기존의 REALM, DPR, RAG 프레임워크보다는 높은 QA 성능을 기록했었으나,
QA task에 최적화된 FiD보다는 높은 성능을 기록하는데에 실패했었습니다.
이 부분은 future work로 고려될 수 있다고 여겨지고 있습니다.