파이썬 판다스 : 엑셀 파일로 데이터프레임 생성
안녕하세요. 이번 포스팅에서는 파이썬 엑셀 파일에서 csv 등 다른 파일로 변환 없이
바로 데이터프레임을 생성하여 다룰 수 있는 판다스의 read_excel 함수에 대해서 알아보고,
작업한 데이터프레임을 엑셀 파일로 다시 내보낼 수 있는 to_excel 함수도 다뤄보겠습니다.
엑셀 파일 가져오기 함수 : read_excel
먼저, 이번 예시에서는 다음과 같은 student.xlsx 파일이 있다고 가정해보겠습니다.

내부 양식이 더 복잡하거나 셀 내에 함수가 들어있어도 상관은 없으며, 시트가 여러개인 경우나
행, 열이 첫 셀부터 시작하지 않는 경우는 뒷 부분에서 다루어보도록 하겠습니다.
일단, 데이터프레임으로 가져오는 방법은 간단합니다.
pd.read_excel('엑셀 파일 디렉토리') 형태로 지정해주시면 가장 기본적인 형태는 완성됩니다.
여기서는 엑셀 파일과 작업하는 파이썬 파일이 같은 폴더에 있다고 가정해보겠습니다.
import pandas as pd
# read_excel 함수의 가장 간단한 사용 예시
df = pd.read_excel('student.xlsx')데이터프레임이 잘 열렸는지 확인해보도록 하겠습니다.
(혹시, 파일을 여는 과정에서 에러가 난다면, engine = 'openpyxl'을 추가로 지정해보세요.)
비어있던 셀들에는 NaN값이 채워지면서, 데이터프레임이 잘 가져와진 것을 확인해보았습니다.
참고로, 오른쪽에 파란색 마법봉 기능을 지원하는 버전이 있는 듯 합니다.
(코랩에서 실행한 경우 위와 같이 나타났습니다.)
이 경우, 위와 같이 필터링 결과를 쉽게 확인할 수 있는 것을 보았습니다.
이제 loc, iloc 함수를 이용한 필터링 대신 엑셀 파일을 다루는 경우에는 위와 같은
필터링 방법을 사용해도 좋을 것으로 생각됩니다.
read_excel 함수 argument
1. sheet_name : 데이터프레임으로 가져올 시트 지정
엑셀 파일 내에서는 시트가 여러개일 수도 있습니다.
기본 값으로는 첫 시트를 가져오는 것으로 설정되어 있으며,
다른 시트를 가져오고 싶은 경우 시트 이름이나 순서 번호(0번 부터 시작 주의, 3번째인 경우 2)
를 인자로 지정해주시면 됩니다.
# 시트 이름 지정
df = pd.read_excel('student.xlsx', sheet_name = "Sheet1")
# 시트 번호 지정(첫 번째는 0, 두 번째는 1, ...)
df = pd.read_excel('student.xlsx', sheet_name = 0)참고로, 여러 시트를 리스트로 지정하거나, None으로 지정하며 모든 시트를 가져올 수 있는데,
이 경우는 딕셔너리 형태로 시트이름 - 해당 시트에 매칭되는 데이터프레임 으로 가져오게됩니다.
2. index_col : 인덱스로 설정할 column 지정
위의 데이터프레임 예시를 보시면, 인덱스 자리(맨 왼쪽의 굵은 글씨)에는 0, 1, 2, 3, 4의
숫자가 새롭게 생성된 것을 확인하실 수 있습니다.
원래 있던 column으로 인덱스로 지정하고 싶은 경우,
index_col = "열 이름" 혹은 index_col = 열의 순서(0번 부터 시작)
형태로 지정해주시면 됩니다.
# 열의 이름으로 지정
df = pd.read_excel('student.xlsx', index_col = "학번")
# 열의 순서로 지정(2번째 column인 "이름"으로 지정)
df = pd.read_excel('student.xlsx', index_col = 1)인덱스 열이 달라진 결과는 위의 결과를 참고하시면 이해가 쉬울 것으로 생각됩니다.
3. header : 시작 행 위치 지정
엑셀 파일이 시작하는 첫 위치가 1번 행이 아닌 경우, 지정해주시면 됩니다.
예를 들어, 아래와 같이 두 번째 행부터 엑셀 파일이 시작하는 경우를 보겠습니다.
이런 경우는 header = 1(0부터 시작하여 두번째 행은 1)로 지정해주시면 됩니다.
# 시작 행 위치 지정
df = pd.read_excel('student.xlsx', header = 1)
4. usecols : 가져올 열 수동 지정
때에따라서는 모든 열을 동시에 가져오고 싶지 않을 수도 있습니다.
이런 경우는 usecols = "A,B,E" 처럼 열의 알파벳을 기준으로 가져오시거나,
usecols = [0, 1, 4] 처럼 열의 순서를 기준으로 일부 열만 가져오시면 됩니다.
# 일부 열만 가져오기
df = pd.read_excel('student.xlsx', usecols = "A,B,E")
# 위와 같은 결과
df = pd.read_excel('student.xlsx', usecols = [0, 1, 4])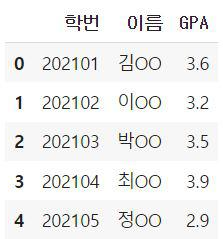
5. names : 열의 이름 리스트 지정
데이터를 불러오는 단계에서 열의 이름을 원하는 형태로 지정 가능합니다.
이 경우 이름의 리스트 원소 개수가 열의 이름 개수와 일치해야함에 유의해주세요.
# 열 이름 수동 지정
df = pd.read_excel('student.xlsx', names = ['num', 'name', 'major', 'second major', 'GPA'])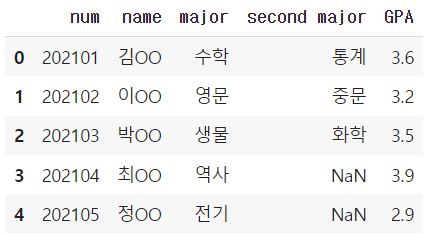
열의 이름들이 지정한대로 바뀐 것을 확인하실 수 있습니다.
6. 기타 유용한 인자
여기서는 다루지 않겠지만, read_excel 함수에서 지원하는 인자들 중 많이 쓰일만한 인자를
몇 가지 더 소개하도록 하겠습니다.
engine : 만일 열려는 엑셀 파일 양식이 .xls 처럼 구버전이거나 .odf 등 다른 양식이라면 지정
skiprows : 모든 행을 전부 가져오고 싶지 않을 경우, 원하는 위치까지 불러올 경우 지정
na_values : 결측값으로 취급할 데이터 값을 정하고 싶은 경우 지정
keep_default_na : False로 지정할 경우 결측치에 NaN이 안채워지고, 빈 칸으로 남아있음
dtype : 데이터 타입을 미리 지정해주고 싶은 column이 있다면 딕셔너리 형태로 지정
이 외에도 정말 많은 argument를 지원한다는 점에 참고해주시면 좋을 듯 합니다.
엑셀 파일 내보내기 함수 : to_excel
to_excel 함수의 사용법은 매우 간단합니다.
원하는 데이터프레임을 기준으로 to_excel 함수 내에 엑셀 파일의 이름과 디렉토리를
지정해주시면 완료됩니다.
# 내보낼 파일 이름과 디렉토리 지정
df.to_excel('student2.xlsx')물론, 이 함수에서도 시트 이름 지정, 인덱스, 소수점 포맷팅 형태, 파일 형식 engine 등
많은 인자를 지원하지만, 여기서는 추가 설명을 생략하도록 하겠습니다.
'Python > Pandas' 카테고리의 다른 글
| [Pandas] 데이터프레임 정렬하기 : sort_values, sort_index 함수 (0) | 2021.12.23 |
|---|---|
| [Pandas] 파이썬 판다스 데이터프레임 인덱싱 총정리(loc, iloc) (0) | 2021.11.27 |
| [Pandas] 파이썬 판다스 데이터프레임 정수형(int), 문자열(str) 타입 변환(astype) (0) | 2021.11.24 |