안녕하세요. 이번 글에서는 헷갈려보이지만 알고보면 굉장히 간단한 판다스 데이터프레임에서 인덱싱을 하는 방법에 대해서 다루어보려고 합니다.
참고로, 데이터프레임은 행은 인덱스를 기준으로, 열은 열 이름을 기준으로 명명되어있다는 점을 기억해두세요!
판다스 데이터프레임 인덱스, column 이름을 기준으로 인덱싱 : loc 함수
다음과 같은 아주 간단한 데이터프레임을 예시로 인덱싱 과정을 설명해보도록 하겠습니다.
학생 5명의 이름과 성적이라고 가정해보겠습니다.

우선 첫 번째로, a1, a2, a3 인덱스를 가진 행을 추출해보겠습니다.
loc 함수 내에 원하는 index들을 리스트로 감싸서 input으로 넣어주면 됩니다!
참고로, csv 파일을 불러온 경우 등에서 기본적으로 0부터 시작하는 숫자 index를 가진 경우에는 df.loc[0:3] 처럼 인덱싱도 가능합니다!
이번에는 name과 english 점수 열만을 대상으로 인덱싱을 해보겠습니다.
모든 행을 가져올 것이기에 첫번째 인자로는 : 로 지정해주고요, 두번째 인자에는 원하는 column의 목록을 리스트 등으로 감싸서 넣어주면 됩니다.
이번에는 행과 열 인덱싱을 동시에 진행해보도록 하겠습니다. a1, a2, a3 인덱스를 가진 행의 name과 english 열만 가져오는 경우도 아래처럼 간단히 해볼 수 있습니다.
loc 함수를 이용한 조건 인덱싱
loc 함수를 이용해서는 조건 인덱싱이 가능합니다. index와 column 이름 대신 인덱싱을 원하는 조건을 loc 함수 내에 적용해주면 됩니다.
예를 들어, 수학 점수가 90점 이상인 학생들의 목록을 찾고 싶을 때는 다음과 같이 해주면 됩니다.
여기서 주의하실 점은, math가 아닌 df(데이터프레임 이름)['math'(열 이름)]의 형태로 작성해주셔야 한다는 점입니다.
두 가지 이상의 조건에 대해서도 적용이 가능합니다. ['a00', 'b00', 'c00'] 목록의 학생 중 수학 성적이 90점 이상인 학생들을 뽑고 싶다고 가정하겠습니다.
각각의 조건을 ()로 감싼 뒤, and 조건이면 &을, or 조건이면 |(엔터 위에 위치한 키)로 적어주시면 됩니다. 조건문에서 in 대신에 isin을 사용한 점도 참고해주시면 좋을 듯 합니다.
판다스 데이터프레임 행, 열의 위치를 기준으로 인덱싱 : iloc 함수
이번에는 iloc 함수로 인덱싱을 하는 예시에 대해서 다루어보겠습니다.
0번 부터 숫자가 시작한다는 점에 주의하시고, 리스트 슬라이싱을 하는 경우처럼 원하는 행, 열의 위치를 지정해주시면 됩니다.
예를 들어, 1 ~ 3번 위치의 행을 가져오고 싶을 때는 아래처럼 작성하시면 됩니다.
리스트 슬라이싱과 방식이 같은 것을 확인해볼 수 있습니다!
열을 기준으로도 마찬가지 인덱싱이 가능합니다. 모든 행을 가져오고 싶다면 첫번째 위치에 : 로 지정해주시면 됩니다.
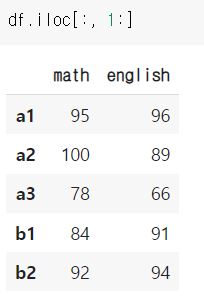
물론, 행과 열을 동시에 인덱싱하는 경우도 마찬가지로 진행할 수 있습니다.

판다스 데이터프레임 빠른 인덱싱 : at, iat 함수
번외로, 단독 원소 인덱싱(하나의 행, 하나의 열 대상)을 하는 경우에 한해서 빠른 인덱싱을 판다스에서 지원합니다. 이 경우는 at, iat 함수를 통해서 할 수 있는데, 다른 포스팅에서 이에 대한 내용을 다루고 있으니 링크를 걸어두도록 하겠습니다.
[Pandas] 데이터프레임 인덱싱 loc, at 차이(iloc, iat 차이)
이번 포스팅에서는 pandas 내 데이터프레임에서 인덱싱을 하는 loc, at과 iloc, iat 함수의 차이를 분석해보도록 하겠습니다. 데이터 프레임으로는 kaggle의 타이타닉 데이터셋을 활용하여 예시를 들어
jimmy-ai.tistory.com
이상으로 판다스 데이터프레임에서 인덱싱을 하는 방법들에 대해서 간단히 다루어보았습니다. 실제로 많이 사용하는 내용 위주로 다루어보았으니 도움이 많이 되시기를 바라겠습니다.
'Python > Pandas' 카테고리의 다른 글
| [Pandas] 파이썬 엑셀 파일 다루기 : read_excel, to_excel (0) | 2021.12.22 |
|---|---|
| [Pandas] 파이썬 판다스 데이터프레임 정수형(int), 문자열(str) 타입 변환(astype) (0) | 2021.11.24 |
| [Pandas] 파이썬 판다스 Deep copy와 Shallow copy 비교(데이터 프레임 복사 copy 함수) (0) | 2021.11.19 |