NAR 기계 번역(NAT) Paper Review
이번 시간에는 문장의 모든 토큰을 한 번에 parallel하게 생성하는 방법인
Non-Autoregressive 기반의 기계 번역 분야의 지평을 열었던 NAT 논문에 대한
주요 내용 요약을 진행해보도록 하겠습니다.
논문의 제목은 "Non-Autoregressive Neural Machine Translation"이며,
ICLR 2018에 등재된 paper입니다.
실험 배경
기존의 신경만 기반 기계 번역의 접근법은 1번에 1토큰씩 디코딩하여 생성하는
Autoregressive(AR) 방식의 번역(AT)이었습니다.
그러나, 이러한 방식은 토큰의 길이가 길어진다면 생성 시간이 많이 소요된다는
단점이 있었고, 이에 1번에 문장의 모든 토큰을 디코딩하여 생성해보려는
Non-Autoregressive(NAR) 방식의 번역(NAT)를 제안하게 되었습니다.

위의 그림처럼 abcde로 이루어진 5개의 토큰을 생성하는 경우
AT와 NAT 방식의 기계 번역의 추론 시간 차이가 뚜렷함을 이해해볼 수 있습니다.
AR 구조 언어 모델
AR 구조 언어 모델의 디코딩 경우에는 아래와 같은 이전까지 토큰 입력이 주어졌을 때,
다음 토큰의 확률 값을 최대화하는 조건부의 maximum likelihood 학습이 진행됩니다.
이전까지 토큰 입력은 ground truth를 가정하는 teacher forcing 방식으로 학습이 진행되는데,
이는 실제 번역 문장의 토큰 분포를 효과적으로 배울 수 있게 도와줍니다.
(실제로 대체로 가장 높은 성능을 보이고 있는 언어 모델 구조입니다.)
NAR 구조 언어 모델
반면, NAR 구조 언어 모델의 디코딩은 다음 식과 같이 이전까지의 생성 토큰 정보를
기반으로 두지않고 진행됩니다.
물론, 이러한 구조는 추론 시간은 매우 단축되지만 추론 시 사용할 수 있는 정보의 양이 제한되어
성능의 한계가 제기되어 왔습니다.
대표적으로 multimodality problem이 예시인데, "Thank you." 문장을 독일어로 번역한다면
“Danke.”, “Danke schon.”, “Vielen Dank.”처럼 여러 어순과 단어 조합의 문장들이 가능한데
NAR 구조에서는 이전 생성 토큰에 조건부 접근이 불가하므로 개별 위치에서의 확률만 따지다가
“Danke Dank.” and “Vielen schon.”와 같이 엉뚱한 문장이 생성되기 쉽다는 것입니다.
NAT 프레임워크 특징
기본적으로는 Transformer 구조의 Encoder-Decoder 프레임워크를 따라가고 있으나
NAT 구조에서 성능을 최대한 높이기 위해 고안된 특징적인 부분을 정리해보도록 하겠습니다.
fertility 도입
NAR 구조의 언어 모델에서는 output sequence의 길이를 예측해야 하는 특징이 있는데,
input의 각 토큰의 영향력을 예측하여 디코더에게 조건부로 넘겨주는 fertility라는
시스템을 도입하여 해결하려 했습니다.
위 그림에 등장한대로 각 단어 토큰의 반복 횟수를 지정(0도 가능합니다.)하여
디코더의 input에 반영하는 것이며, 학습 과정에서 아래 식의 pF라고 작성된 fertility 분포에서
확률 값을 조건부 sequence 생성 확률에 곱하는 식으로 반영하여 학습이 진행됩니다.
해당 논문에서는 fertility의 장점을 다음과 같이 요약했습니다.
1. 비지도 학습 문제를 두 개의 지도 학습 문제로 reduce하는 효과적인 방법
2. multimodality problem 완화 가능
3. complete alignment statistics 제공 효과(디코더가 인코더의 burden을 일부 해소)
디코딩 방법 종류
인코더에서 예측된 fertility 분포를 디코더의 input으로 활용하는 방법에 따라
3가지 방법의 디코딩 방법을 해당 paper에서 제안하고 있습니다.
1. Argmax decoding : 최대 확률을 가지는 fertility 결과를 기반으로 디코딩
2. Average decoding : fertility 확률의 평균을 낸 뒤 반올림한 결과를 기반으로 디코딩
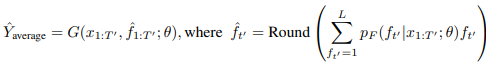
3. Noisy parallel decoding(NPD) : 생성된 토큰에 대해 teacher AR 모델에서의 확률을
다시 구하여 최대가 되는 fertility를 기반으로 디코딩
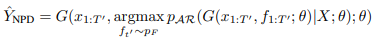
knowledge distillation fine-tuning
양쪽 언어 간의 구조 차이 등으로 인하여 fertility의 도입만으로 multimodality problem를
완전히 해결하는하는 것은 어렵기에 AR 구조의 언어 모델을 teacher로 삼아 여기서
생성된 greedy output을 ground truth로 가정하여 학습을 진행하는
sequence-level knowledge distillation의 결과 loss를
같이 포함하여 fine-tuning을 진행했었습니다.(LKD)
또한, AR 모델에서 각 토큰의 생성 확률과 NAR 모델에서의 각 토큰의 생성 확률 간의
reverse KL divergence를 구하는 식(LRKL)으로
word-level knowledge distillation의 결과 loss도 fine-tuning 과정에서 포함하였습니다.
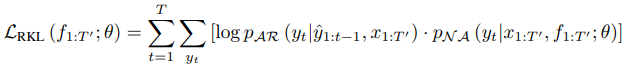
이 두가지 term을 조합하여 최종 fine-tuning loss(LFT)는 다음과 같이 정의하였습니다.

여기서 LRL은 강화학습에서 사용되는 방법과 유사한 방식의 term을 의미하고,
LBP는 일반적인 역전파 알고리즘의 term을 의미하게 설계하였습니다.
결과 분석
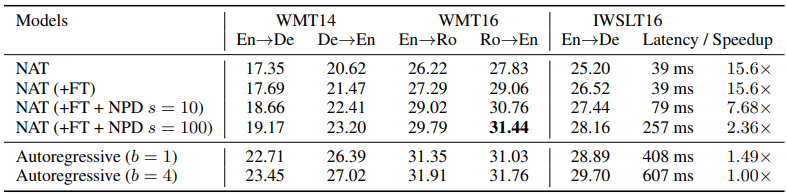
세 가지 기계 번역 벤치마크 데이터셋에 대하여 전반적으로 AT 모델에 비하여
BLEU 점수 성능은 약간씩 떨어지는 모습을 보이고는 있었습니다.
그러나, NPD 디코딩 방식을 적용하지 않은 경우에는 15배 가량 추론 속도가 빨랐으며,
NPD 샘플 100개까지 적용 시에도 2배 이상 빠르며 Ro -> En의 WMT16에서는 오히려
beam = 1일 때의 AR 모델의 성능을 압도하는 결과도 기록했었습니다.
또한, KD fine-tune 및 NPD 디코딩 방식은 성능 향상에 매우 중요함을 알 수 있었습니다.
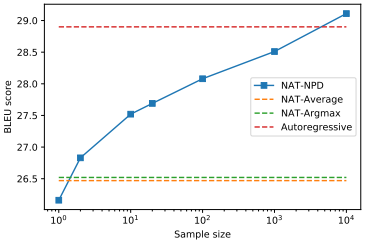
Argmax와 Average 방식의 디코딩 간의 성능은 거의 비슷했습니다.
그러나 NPD 방식의 디코딩은 성능 향상에 중요한 영향을 보였으며,
특히 샘플 사이즈가 클수록 성능이 좋아지는 경향이 뚜렷했습니다.
(그러나 샘플이 너무 많으면 추론 시간이 오래걸려 성능이 AR보다 좋아지는 것처럼 보여도
장점이 흐려집니다.)
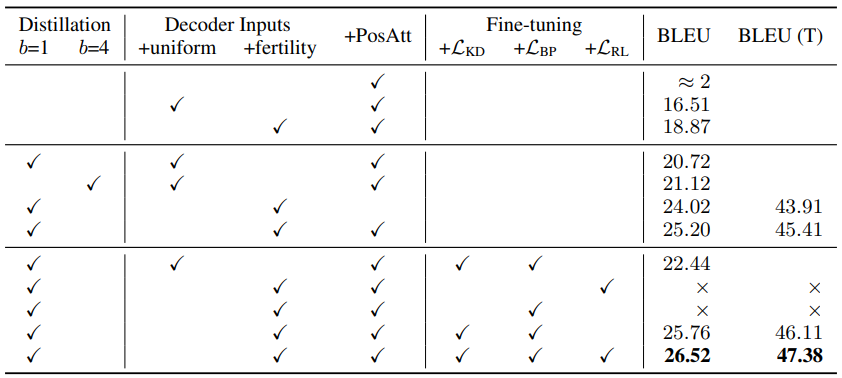
위의 Table 2 결과를 살펴보면 디코더 input으로 fertility의 결과가 반영된 것의 여부는
3 BLEU 점수 차이 이상의 큰 성능 차이를 야기하는 것을 볼 수 있습니다.
또한 fine-tuning 과정 시에 BP, RL term의 loss를 모두 반영하는 것도
성능 향상에 있어서 중요했으며, KD가 잘되어 teacher 모델의 greedy output과의
BLEU(T)가 높게 학습된다면 실제 데이터와의 최종 BLEU도 높게 학습되는 경향이 있었습니다.