NLP DPR Paper Review
이번 글에선 Open Domain Question Answering(ODQA) 분야에서 관련 문서 Retriever로
현재까지도 강력한 성능을 자랑하며 사용되고 있는 DPR 프레임워크에 대하여 발표했던
논문의 주요 내용들을 요약해보도록 하겠습니다.
논문의 제목은
"Dense Passage Retrieval for Open-Domain Question Answering"이며,
EMNLP 2020에 등재된 paper입니다.
실험 배경
ODQA 분야에서 질문과 관련이 깊은 후보 문서 탐색(Retrieval) 후
해당 문서들 내에서 답변의 위치를 찾는 과정(Reader)으로 구성된 프레임워크가
좋은 성능을 보이고 있음이 나타났고, 이전의 Retriever 모델 구조로는
TF-IDF나 BM25같은 키워드 기반 sparse vector를 사용하는 방식이 사용됐었습니다.
(수 많은 키워드에 대하여 일일이 등장 여부(또는 등장 횟수)를 벡터로 기록하게 됩니다.)
그러나 위의 sparse vector 방식으로는 동의어나 paraphrase가 활용된 문맥의 정보를
반영하기가 매우 어렵다는 단점이 있습니다.
여기서는 트랜스포머 인코딩 모델인 BERT 구조를 활용하여 문맥의 정보를
dense vector 형태로 저장하는 시도를 하였으며, 관련 문서 Retrieval의 성능을
크게 향상시키는 기여를 하는데 성공하였습니다.
(벡터의 각 숫자는 키워드 등장 횟수같은 sparse한 값이 아니라
문맥의 내재된 값을 실수 형태(dense)로 저장합니다.)
이후 Retriever-Reader 기반 ODQA에 관련된 대부분의 논문들에서 해당 프레임워크를
Retriever 모델로 사용할 정도로 해당 task 분야에 막대한 영향을 끼친 paper입니다.
DPR 프레임워크 특징
DPR(Dense Passage Retrieval)의 구조는
질문 인코딩 결과와 문서 인코딩 결과의 내적 값이 클수록 유사도가 높다고 간주하는 구조입니다.
먼저, 질문과 문서 간 유사도를 수식으로 표현하면 다음과 같습니다.

여기서 $E_Q, E_P$는 각각 질문과 문서를 인코딩하여 벡터를 반환하는 BERT 인코더입니다.
모델 학습은 아래 수식의 Contrastive Learning과 유사한 loss 함수를 통해서 진행됩니다.
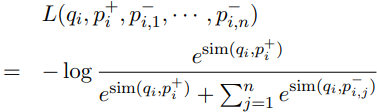
여기서 $p^+$로 작성된 positive passage는 데이터셋 내의 질문과 매칭되는 ground truth이며,
$p^-$로 작성된 negative passage는 질문과 관련도가 낮은 passage를 의미하는데,
여기서 문제를 조금 더 어렵게 설정하기 위해 hard negative를 설정하는 과정이 중요합니다.
해당 연구에서는 negative passage의 기준은 다음과 같이 설정했었습니다.
1) 코퍼스 내에서 랜덤하게 추출한 passage
2) BM25에 의해 선별되었으나, 답변을 포함하지 않는 passage
3) 데이터셋 내의 다른 question과 관련된 passage(Gold라고 칭함)
참고로, 유사도 계산 과정에서 batch 내의 질문들을 인코딩한 행벡터들을 아래로 쌓은 행렬 Q와
해당 배치 내 문서들을 인코딩한 행벡터들을 아래로 쌓은 행렬 P에 대하여
$QP^T$의 행렬 곱 결과에서 대각성분들은 positive pair 간의 유사도이며,
다른 성분들은 negative pair 간의 유사도이므로, 이 성질을 이용하여 효율적으로
위 식의 loss 값을 계산할 수 있음을 언급하고 있습니다.(In-Batch라고 칭함)
결과 분석

5가지 종류의 QA 벤치마크 데이터셋에 대하여 BM25 단독, DPR, 그리고 BM25+DPR 결합의
3가지 모델에 대한 문서 탐색 정확도 성능을 비교한 결과는 위의 표와 같았습니다.
(top-20 및 top-100 문서 내에 답변이 포함된 비율을 측정한 것이었습니다.)
참고로, 후보 passage로는 위키피디아 문서를 전처리한 2100만 여개의 문서를 활용하였으며,
각 passage는 100 words 정도의 단위로 구성했었습니다.
BM25에서 계산된 가중치와 결합한 경우 성능의 향상 여부는 데이터셋마다 들쭉날쭉했으며,
여러 종류의 데이터셋을 혼합하여 학습을 진행한 경우 성능 향상이 되는 경향이 나타났습니다.

동일한 개수의 탐색 문서 수인 경우 데이터셋(질문-문서 pair의 개수)의 크기에 따른 성능 변화
그래프를 위의 그림에 나타냈었습니다.
그 결과, 단 1000개의 example만으로도 BM25의 성능을 압도했으며(Sample efficiency),
데이터셋의 크기가 커질수록 성능이 조금씩 향상되는 경향이 나타났었습니다.
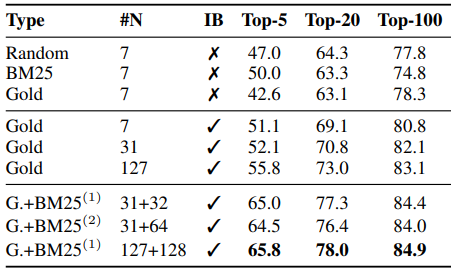
랜덤, BM25 오답, Gold 3가지 종류의 negative passage에 대하여 샘플 개수 및 In-Batch 적용
여부에 대한 결과를 위의 표에 나타냈었습니다.
Gold와 BM25 오답 passage의 혼합 데이터를 사용한 경우 강력한 성능을 나타냈었으며,
negative data의 개수가 많아야 성능이 좋아지는 경향도 뚜렷했습니다.
여기서는 특히 높은 BM25 점수를 받았지만, 답변은 포함하고 있지 않는 BM25 오답 문단을
hard negative로 칭하면서 중요성을 강조하고 있는데, Gold passage에 batch 내 질문별로
BM25 오답 문서를 1개씩 추가한 경우 성능 향상 폭이 컸지만, 2개씩을 추가한 경우에는
추가적인 성능 향상 효과는 거의 없었습니다.

DPR Retriever 구조를 ODQA task에 장착하여 성능을 비교한 결과, 강력한 문서 탐색
성능을 기반으로 SQuAD를 제외한 4가지 벤치마크에 대하여 모두 SOTA를 기록했었습니다.
(Reader로는 BERT로 답변 span의 위치를 분류하는 구조를 사용했었습니다.)
여기에서도 여러 종류의 데이터셋을 혼합하여 학습을 진행한 결과 성능이 대체로 더 좋았으며,
BM25의 가중치 혼합 여부의 영향은 데이터셋마다 상이했습니다.