파이썬 사이킷런 스케일러 사용 예제, 특징 정리
안녕하세요. 이번 글에서는 파이썬 scikit-learn 라이브러리에서
각 feature의 분포를 정규화 시킬 수 있는 대표적인 Scaler 종류인
StandardScaler, MinMaxScaler 그리고 RobustScaler에 대하여
사용 예제와 특징을 살펴보도록 하겠습니다.
여기서는 아주 간단한 예시로 0~10의 숫자가 차례로 있는 x1 column과
0~10의 제곱수가 차례로 있는 x2 column의 정규화 결과를
각 Scaler에서 비교해보며 대략적인 특징을 살펴보겠습니다.
import pandas as pd
import numpy as np
df = pd.DataFrame({'x1' : np.arange(11), 'x2' : np.arange(11) ** 2})
df
StandardScaler : 평균 0, 표준편차 1 기준 정규화
StandardScaler는 각 열의 feature 값의 평균을 0으로 잡고,
표준편차를 1로 간주하여 정규화시키는 방법입니다.
사용 방법은 Scaler를 import한 뒤, 데이터셋을 fit_transform시켜주시면 됩니다.
이 사용법은 뒤에서 설명할 다른 Scaler에서도 동일합니다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df_std = scaler.fit_transform(df)
pd.DataFrame(df_std, columns = ['x1_std', 'x2_std'])
각 데이터가 평균에서 몇 표준편차만큼 떨어져있는지를 기준으로 삼게 됩니다.
데이터의 특징을 모르는 경우 가장 무난한 종류의 정규화 중 하나입니다.
MinMaxScaler : 최솟값 0, 최댓값 1 기준 정규화
MinMaxScaler는 각 feature의 최솟값과 최댓값을 기준으로
0~1 구간 내에 균등하게 값을 배정하는 정규화 방법입니다.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df_minmax = scaler.fit_transform(df)
pd.DataFrame(df_minmax, columns = ['x1_minmax', 'x2_minmax'])
이상치에 민감하다는 단점이 있긴 하지만,
각 feature의 범위가 모두 0~1로 동등하게 분포를 바꿀 수 있다는 장점이 있습니다.
RobustScaler : 중앙값 0, 사분위수 IQR 기준 정규화
RobustScaler는 각 feature의 median(Q2)에 해당하는 데이터를 0으로 잡고,
Q1, Q3 사분위수와의 IQR 차이 만큼을 기준으로 정규화를 진행합니다.
공식 : (데이터 값 - Q2) / (Q3 - Q1)
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
df_robust = scaler.fit_transform(df)
pd.DataFrame(df_robust, columns = ['x1_robust', 'x2_robust'])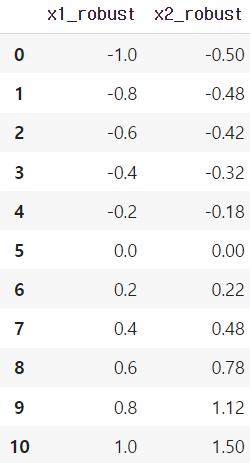
해당 정규화 방법은 이상치에 강한 특징을 보이기에 RobustScaler라는 이름이 붙었으며,
이상치가 많은 데이터를 다루는 경우 유용한 정규화 방법이 될 수 있습니다.
'Python > Sklearn' 카테고리의 다른 글
| [Sklearn] 파이썬 TF-IDF 구하기, 코사인 유사도로 비슷한 문서 찾기 (2) | 2022.02.22 |
|---|---|
| [Sklearn] 파이썬 DBSCAN 클러스터링 구현 및 시각화 예제 (0) | 2022.02.17 |
| [Sklearn] 파이썬 사이킷런 PCA 구현 및 시각화 예제 (0) | 2022.02.12 |