파이썬 사이킷런 DBSCAN 군집화 과정
안녕하세요. 이번 글에서는 파이썬의 scikit-learn 라이브러리를 이용하여
DBSCAN 클러스터링 과정을 구현해보고, 시각화 결과를 비교하여
최적의 파라미터를 추적해보는 예제에 대해서 다루어보도록 하겠습니다.
데이터셋 로드 및 정규화
우선, 이번 글에서는 캐글에 있는 아래 사이트의 데이터를 사용하여 군집화를 진행해보겠습니다.
Mall Customers Clustering Analysis
Explore and run machine learning code with Kaggle Notebooks | Using data from Mall Customer Segmentation Data
www.kaggle.com
import pandas as pd
df = pd.read_csv('Mall_Customers.csv')데이터프레임의 구성은 아래와 같습니다.

5가지 feature, 200개의 행을 가지고 있는 간단한 데이터셋입니다.
여기서는 보다 용이한 시각화를 위하여 가장 뒤쪽 2개 열인 Annual Income, Spending Score
열들만 사용하여 2개의 feature에 대한 고객 군집화를 진행해보겠습니다.
DBSCAN은 feature 간 거리를 기준으로 클러스터를 구성하는 알고리즘으로,
이 과정을 위해서는 정규화가 필수적입니다.
아래 코드에서는 예시로 StandardScaler을 이용한 정규화를 진행하였습니다.
from sklearn.preprocessing import StandardScaler
# 두 가지 feature를 대상
data = df[['Annual Income (k$)', 'Spending Score (1-100)']]
# 정규화 진행
scaler = StandardScaler()
df_scale = pd.DataFrame(scaler.fit_transform(df), columns = data.columns)
클러스터링 과정 구현
DBSCAN 군집화를 위해서는 현재 군집 상태로부터 최대 탐색 거리를 의미하는 epsilon 값과
클러스터로 구성되기 위한 최소 샘플 개수인 min_samples 값을 지정해주어야 합니다.
사이킷런의 DBSCAN 메소드를 import한 뒤,
이 두 값을 각각 eps와 min_samples 인자에 지정하여
위에서 정규화시킨 데이터를 클러스터링해주시면 됩니다.
예시로 eps = 0.5, min_samples = 2로 정한 뒤 군집화를 진행해보겠습니다.
from sklearn.cluster import DBSCAN
# epsilon, 최소 샘플 개수 설정
model = DBSCAN(eps=0.5, min_samples=2)
# 군집화 모델 학습 및 클러스터 예측 결과 반환
model.fit(df_scale)
df_scale['cluster'] = model.fit_predict(df_scale)클러스터링 결과 시각화
우선, 바로 위에서 진행한 군집화의 결과를 시각화해보도록 하겠습니다.
여기서는 군집화 직후에 클러스터의 개수를 모르는 상황이므로,
클러스터링 결과 숫자의 최대값을 추적했다는 점에 유의해주세요.
또한, 이상치의 클러스터 번호는 -1로 저장되기에, -1부터 최대 숫자까지
클러스터별 산점도를 따로 그리는 예시를 구현해보았습니다.
import matplotlib.pyplot as plt
plt.figure(figsize = (8, 8))
# 이상치 번호는 -1, 클러스터 최대 숫자까지 iteration
for i in range(-1, df_scale['cluster'].max() + 1):
plt.scatter(df_scale.loc[df_scale['cluster'] == i, 'Annual Income (k$)'], df_scale.loc[df_scale['cluster'] == i, 'Spending Score (1-100)'],
label = 'cluster ' + str(i))
plt.legend()
plt.title('eps = 0.5, min_samples = 2', size = 15)
plt.xlabel('Annual Income', size = 12)
plt.ylabel('Spending Score', size = 12)
plt.show()
낮은 min_samples로 인하여, 0번 클러스터에 너무 많은 값들이 같은 군집으로
포함된 듯한 모습을 살펴볼 수 있었습니다.
이번에는, min_samples = 12로 고정해보고, eps 값을 바꿔보며
군집화를 여러차례 실행한 결과를 동시에 시각화해보겠습니다.
# 다중 플롯 동시 시각화
f, ax = plt.subplots(2, 2)
f.set_size_inches((12, 12))
for i in range(4):
# epsilon을 증가시키면서 반복
eps = 0.4 * (i + 1)
min_samples = 12
# 군집화 및 시각화 과정 자동화
model = DBSCAN(eps=eps, min_samples=min_samples)
model.fit(df_scale)
df_scale['cluster'] = model.fit_predict(df_scale)
for j in range(-1, df_scale['cluster'].max() + 1):
ax[i // 2, i % 2].scatter(df_scale.loc[df_scale['cluster'] == j, 'Annual Income (k$)'], df_scale.loc[df_scale['cluster'] == j, 'Spending Score (1-100)'],
label = 'cluster ' + str(j))
ax[i // 2, i % 2].legend()
ax[i // 2, i % 2].set_title('eps = %.1f, min_samples = %d'%(eps, min_samples), size = 15)
ax[i // 2, i % 2].set_xlabel('Annual Income', size = 12)
ax[i // 2, i % 2].set_ylabel('Spending Score', size = 12)
plt.show()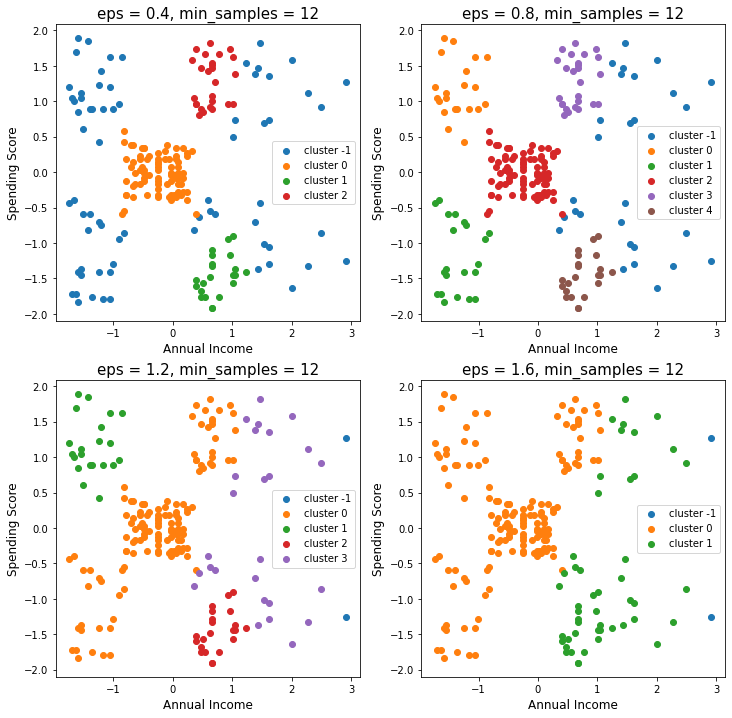
eps이 너무 낮으면 비교적 가까운 점들도 같은 군집으로 형성되기 어려웠고,
eps이 높은 경우는 대부분의 점들이 모두 같은 군집으로 포함되었습니다.
위의 결과에서는 eps = 0.8의 경우가 가장 이상적인 군집화의 결과로 판단되었습니다.
다중 플롯을 설정하는 자세한 방법은 아래 글에서 남겨두었으니
위 과정에서 추가 시각화가 필요하신 분들은 참고해보시면 좋을 듯 합니다.
[Matplotlib] 파이썬 그래프 여러개 다중 플롯(subplot) 초간단 설정 방법
파이썬 plt 그림 여러개 간단하게 설정하기 : plt.subplots() 안녕하세요. 이번 포스팅에서는 파이썬 matplotlib 라이브러리에서 그래프 여러개를 한 화면에 동시에 나타내고, 각 그래프의 세부 사항들
jimmy-ai.tistory.com
'Python > Sklearn' 카테고리의 다른 글
| [Sklearn] 파이썬 정규화 Scaler 종류 : Standard, MinMax, Robust (0) | 2022.02.18 |
|---|---|
| [Sklearn] 파이썬 사이킷런 PCA 구현 및 시각화 예제 (0) | 2022.02.12 |
| [Sklearn] 파이썬 t-SNE 차원 축소 시각화 예제 (2) | 2022.02.10 |