파이썬 네이버 주식 정보 크롤링 예시
이번 포스팅에서는 BeautifulSoup 모듈을 활용하여
매우 간단하게 네이버 주식 사이트의 정보를 크롤링해보는
예제를 다루어보도록 하겠습니다.
먼저 네이버 금융의 국내증시 사이트에 접속을 해보도록 하겠습니다.

금융 정보에 대한 굉장히 많은 정보가 있는데요.
여기서는 이 중 현재 코스피의 수치와 등락률을 대상으로
크롤링을 진행해보는 예제를 다루어보도록 하겠습니다.
참고로, 여기서는 크롬 브라우저를 기준으로 설명을 진행해보도록 하겠습니다.
(다른 브라우저들도 방법은 대체로 비슷합니다.)
개발자 도구를 열어 크롤링 준비
크롤링을 위하여 F12를 눌러 개발자 도구를 켠 뒤, 아래 그림의 파란색으로 표시한 부분의
화살표 모양 버튼을 클릭하여 크롤링 준비를 마치겠습니다.

BeautifulSoup 웹사이트 크롤링 준비
먼저 코스피 수치의 데이터를 가져오기 위하여 해당 값의 HTML태그를 분석해야 합니다.
아래 그림처럼 원하는 위치에 커서를 갖다대면, 해당 위치의 태그가 나타나게 됩니다.
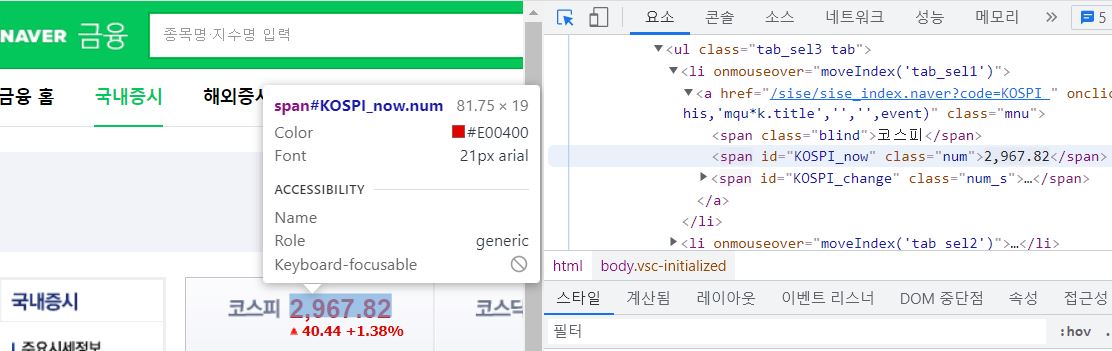
두 가지 방법으로 코스피의 수치인 2967.82라는 값(변동 가능)에 접근이 가능합니다.
첫 번째는 span 클래스의 num 이름을 가지는 객체를 기준으로 삼는 것이고,
두 번째는 KOSPI.now라는 id 이름을 기준으로 삼는 것입니다.
두 방법의 예시를 보여드리기 전에, bs4 라이브러리에서 해당 웹페이지의 태그를
가져와 정보를 추출할 준비를 하도록 하겠습니다.
import urllib.request
from bs4 import BeautifulSoup
# 네이버 금융 국내증시 메인 사이트 주소
url = "https://finance.naver.com/sise/"
# 웹사이트 정보 요청
page = urllib.request.urlopen(url)
# 해당 페이지는 cp949 방식의 인코딩 사용
html = page.read().decode('cp949')
# html.parser로 html 형식 태그에서 데이터 추출 준비
soup = BeautifulSoup(html, 'html.parser')다른 웹사이트에서는 'utf8', 'euc-kr' 등의 인코딩 방식을 사용하는 경우도 있어,
이 부분은 시도를 여러번 해보시는 것이 좋습니다.
클래스 이름 기준 크롤링 방법 : select 메소드
span 클래스의 num 객체라는 정보를 사용한 경우는
select 메소드를 사용하여 가져올 수 있습니다.
아래처럼 코드를 작성하고 결과를 확인해보겠습니다.
soup.select('span.num')
# 결과
[<span class="num _au_real_list">@code@</span>,
<span class="num " id="KOSPI_now">2,965.88</span>,
<span class="num " id="KOSDAQ_now">987.57</span>,
<span class="num " id="KPI200_now">393.71</span>]span.num이라는 이름을 input으로 넣어주시면 됩니다.
여기서는 span 클래스의 num 객체가 총 4개가 존재하는데요.
이 중 2번째(1번 위치) 값이 저희가 추출을 원하는 값이기에,
인덱싱을 진행한 뒤, string 속성을 가져와 원하는 정보까지 도달해보겠습니다.
이후, 문자열 메소드로 천의 자리 수 콤마를 제거하고 float 자료형 변환까지 가능합니다.
soup.select('span.num')[1]
# <span class="num " id="KOSPI_now">2,965.88</span>
soup.select('span.num')[1].string
# 2,965.88
float(soup.select('span.num')[1].string.replace(',', ''))
# 2965.88(실수 숫자 자료형)
id 기준 크롤링 방법 : find 메소드
이번에는 KOSPI_now라는 id를 기준으로 크롤링을 진행해보겠습니다.
id를 기준으로 데이터를 가져올 때는 find 메소드를 사용하게 됩니다.
input으로 id = 'KOSPI_now' 처럼 지정해주시면 됩니다.
여기서는 해당 id를 가진 객체가 1개 뿐이라 결과가 바로 산출되었습니다.
이후, 위와 마찬가지로 string 속성을 가져와 원하는 데이터까지 도달 가능합니다.
soup.find(id = 'KOSPI_now')
# <span class="num " id="KOSPI_now">2,965.88</span>
soup.find(id = 'KOSPI_now').string
# '2,965.88'
심화 예제 : 코스피 등락률 크롤링
이번에는 약간 더 복잡한 형태로 작성되어 있는
코스피 등락률 정보를 가져와보도록 하겠습니다.

개발자 도구를 이용하여 KOSPI_change id를 가진 객체
혹은 span 클래스의 num_s 객체인 것을 확인하실 수 있습니다.
두 가지 모두 크롤링에서 사용 가능하나, 이번에는 id를 이용한 방법만 살펴보겠습니다.
soup.find(id = 'KOSPI_change')
'''
<span class="num_s " id="KOSPI_change">
<span class="nup"></span>38.50 +1.32%<span class="blind">상승</span>
</span>'''find 메소드로 정보를 가져와보니 이번에는 '38.50 +1.32%'라는 정보와 '상승'이라는
두 가지 정보가 태그 내에 숨겨져 있는 것을 확인해볼 수 있었습니다.
이처럼 여러 태그가 동시에 얽혀 있다면, 바로 string 속성을 가져올 수는 없으며,
contents 속성을 통하여 세부 태그 정보에 각각 접근 후 string 속성을
적용해주시면 됩니다.
soup.find(id = 'KOSPI_change').contents
'''
['\n',
<span class="nup"></span>,
'38.50 +1.32%',
<span class="blind">상승</span>,
'\n']'''
soup.find(id = 'KOSPI_change').contents[2]
# '38.50 +1.32%'
soup.find(id = 'KOSPI_change').contents[2].split()
# ['38.50', '+1.32%']
soup.find(id = 'KOSPI_change').contents[3].string
# '상승'줄바꿈 기호를 포함하여 총 5개의 contents로 구성되어 있으며,
이 중 원하는 정보가 포함된 위치에 대하여 인덱싱을 진행해주시면 됩니다.
최종 string 자료형까지 도달한 이후에는 split 등 문자열 메소드를 적용하여
파싱을 이어서 진행해주시면 됩니다.
'Python > Crawling' 카테고리의 다른 글
| 파이썬 Selenium으로 Network 패킷 크롤링 예제 (0) | 2024.06.21 |
|---|---|
| 셀레니움에서 텍스트 입력 시 줄 바꿈이 안될 때 해결 방법 (1) | 2023.10.13 |
| 셀레니움 h1, strong 등 HTML 태그 적용 텍스트 삽입 방법 예제 (0) | 2023.09.26 |