파이썬 판다스 데이터프레임 합치기 함수 : pd.merge vs pd.concat
안녕하세요. 이번 시간에는 판다스에서 데이터프레임을 병합할 수 있는
두 함수인 pd.merge와 pd.concat 함수의 용도와 결과 차이에 대해서
간단히 비교해보는 시간을 가져보도록 하겠습니다.
먼저, 아래와 같이 간단한 데이터프레임 두 개가 각각 df_1, df_2 변수에
저장된 상태라고 가정해보겠습니다.

위 데이터프레임 두 개를 병합하는 여러 예시를 통해서
합쳐지는 형태와 원리를 이해해보겠습니다.
merge 함수 : 내부 조인 (inner join)
가장 기본적인 예시로, 공통된 키의 값이 있는 경우에만
데이터프레임을 병합하는 내부 조인의 예시를 살펴보겠습니다.
예를 들어, 이름을 기준으로 df_1, df_2를 내부 조인하면
결과는 다음과 같이 나타나게 됩니다.
import pandas as pd
pd.merge(df_1, df_2, on = '이름')양쪽 데이터프레임 모두 '김', '이' 이름을 가진 행이 존재하여
해당 행들의 4개의 과목 점수가 모두 나타난 것을 확인할 수 있습니다.
'박'이나 '최' 이름을 가진 행은 한쪽 데이터프레임에만 존재하여
여기서는 나타나지 않게 되었습니다.
만일, 양쪽 데이터프레임에서 사용하는 column의 이름이 다른 경우는
left_on, right_on으로 column의 이름을 따로 지정해주시면 됩니다.
df_2의 이름 column이 'name'으로 바뀐 경우의 예시입니다.
pd.merge(df_1, df_2, left_on = '이름', right_on = 'name')
또한, 양쪽 다 key가 아닌 column이 중복되어 있는 경우,
가령 df_1, df_2 모두에 수학 column이 있다면
수학_x, 수학_y 처럼 각 열들을 보존하는 결과를 나타내게 됩니다.
merge 함수 : 외부 조인 (left join, right join, outer join)
외부 조인의 경우도 merge 함수로 결과를 반환할 수 있습니다.
left join은 왼쪽 데이터프레임에만 있는 행도 가져오게되며,
right join은 오른쪽에만 있는 경우도,
outer join은 한쪽에만 있는 경우는 모두 행을 가져옵니다.
예시를 통하여 사용법과 실행 결과를 살펴보도록 하겠습니다.
먼저, left join의 예시입니다. how 인자를 'left'로 지정해주시면 됩니다.
pd.merge(df_1, df_2, on = '이름', how = 'left')df_1에만 있던 '박' 이름에 대한 행이 추가된 것을 확인하였습니다.
다만, 영어와 역사 점수에 해당하는 값은 df_2에만 있기에,
해당 값들은 NaN값으로 결측치로 남게 되었음에 주목해주세요.
이번엔 right join을 해보겠습니다. 마찬가지로 how인자로 지정해주시면 됩니다.
pd.merge(df_1, df_2, on = '이름', how = 'right')이번에는 df_2에만 있던 '최' 이름에 대한 행이 추가되었습니다.
이 경우는 df_1에만 있던 국어와 수학 점수에 해당하는 값들이
결측치로 남은 것을 확인해보았습니다.
마지막으로 outer join의 예시입니다. 이 경우는 한 쪽에만 있는 행들을
모두 가져와 데이터프레임을 병합하게 됩니다.
pd.merge(df_1, df_2, on = '이름', how = 'outer')한쪽 데이터프레임에만 있던 '박', '최' 이름에 대한 행이 모두 추가되어
병합된 결과를 확인할 수 있었습니다.
merge 함수 : 카테시안 곱(cross product)
이 기능은 판다스 1.2.0 버전 이후에서만 지원하고 있는 것으로,
모든 가능한 조합을 전부 나타내는 카테시안 곱을 merge 함수에서
지원하고 있습니다.
사용 방법은 간단합니다. how = 'cross'로 설정해주면 되는데요,
이 때, key column을 지정하는 on 변수는 지정하면 안됩니다.
pd.merge(df_1, df_2, how = 'cross')양쪽의 행을 1개씩 가져와 이어 붙인 조합들을 나열한 것을 확인할 수
있었습니다. 이 경우, df_1, df_2 모두 3개의 행을 가지고 있었으므로,
총 3 * 3 = 9개의 가능한 조합이 있었습니다.
concat 함수 : 행 방향으로 데이터프레임 합치기
위의 merge 함수는 데이터프레임 key column의 값을 기준으로 병합을 시도한
예시라고 볼 수 있었습니다.
이번에 다룰 concat 함수는 데이터프레임 내 값과는 상관없이,
단순히 행 혹은 열 방향으로 값들을 이어붙이는 상황이라고 생각해주시면
이해가 쉬울 것으로 생각됩니다.
먼저, 가장 기본적으로 행 방향으로 데이터를 합치는 결과를 보겠습니다.
사용 시, 리스트 등 자료형에 합칠 데이터프레임의 목록을 작성해주시는 형태로
input을 넣어주셔야합니다. 3개 이상의 데이터프레임을 합치는 것도 가능합니다.
pd.concat([df_1, df_2])
# 잘못된 예시
pd.concat(df_1, df_2)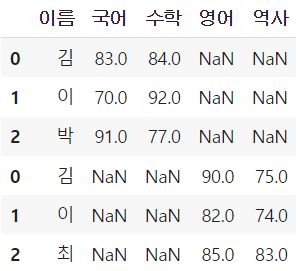
merge의 결과와 비교를 해보시면, 우선 '김', '이' 이름을 가진 행들이
결과가 하나로 합쳐진 것이 아니라, 따로따로 들어온 것을 확인해볼 수 있습니다.
또한, index가 초기화되지 않고, 원래 데이터프레임의 인덱스를 보존하여
합쳐진 결과에서도 반영하고 있는 점도 주목해주시면 좋습니다.
concat 함수 : 열 방향으로 데이터프레임 합치기(axis = 1)
이번에는 열 방향으로 데이터프레임을 합쳐보겠습니다.
이 경우, axis 인자를 1로 지정해주시면 됩니다.
pd.concat([df_1, df_2], axis = 1)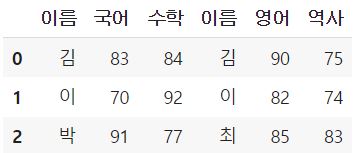
각 행들이 오른쪽 방향으로 붙어서 데이터프레임이 병합된 것을
확인해볼 수 있었습니다.
이 때, 이름 column이 2개로 중복된 점에 주의해주셔야하며,
'김', '이' 이름을 가진 행들이 같은 행에 붙은 것은
행의 값이 같아서가 아니라, 순서 상으로 같은 위치에 있었기 때문입니다.
이렇게 값을 기준으로 데이터프레임을 조인하는 merge 함수와
단순히 한쪽 방향으로 데이터들을 이어 붙이는 concat 함수의 차이에 대해서
살펴보았습니다. 감사합니다.
'Python > Pandas' 카테고리의 다른 글
| [Pandas] 리스트, 딕셔너리 자료형을 데이터프레임, Series로 바꾸기 (0) | 2022.01.08 |
|---|---|
| [Pandas] 파이썬 판다스 행, 열에 함수 적용 : pd.transform() (0) | 2021.12.29 |
| [Pandas] 데이터프레임 정렬하기 : sort_values, sort_index 함수 (0) | 2021.12.23 |