파이썬 plt 히스토그램 함수 : plt.hist()
안녕하세요. 이번 글에서는 파이썬 시각화 라이브러리 matplotlib에서
데이터의 분포를 살필 수 있는 히스토그램 함수인 plt.hist()의
사용 방법을 자세하게 살펴보도록 하겠습니다.
우선, 다음과 같이 10000개의 정규분포 데이터를 샘플링하겠습니다.
import numpy as np
data = np.random.randn(10000)이제, 위에서 샘플링한 변수인 data를 가지고 히스토그램을 그려보도록 하겠습니다.
우선, 가장 기본형의 히스토그램은 다음 코드처럼 그릴 수 있겠습니다.
import matplotlib.pyplot as plt
plt.hist(data)
plt.show()
하지만, 아직 히스토그램을 완성시키기에는 너무 밋밋해보입니다.
이제 히스토그램을 꾸미는 방법을 하나씩 살펴보도록 하겠습니다.
파이썬 히스토그램 색깔, 폭(bin 개수), 선의 색깔 설정
먼저, 다음과 같이 히스토그램의 색깔을 입히고 투명도도 조절해보겠습니다.
색깔은 color인자, 투명도는 alpha인자로 조절해주시면 됩니다.
plt.hist(data, color = 'green', alpha = 0.4)
plt.show()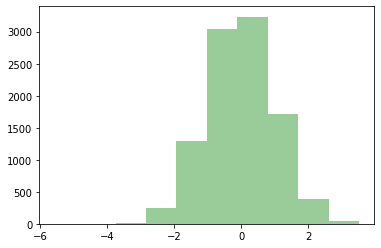
그러나, 여전히 히스토그램의 한 칸의 크기가 너무 커서 데이터의 분포가
제대로 반영되지 않는 것으로 추정됩니다.
bins 인자에 원하는 칸의 수를 입력해서 한 칸의 크기를 조절해보겠습니다.
plt.hist(data, color = 'green', alpha = 0.4, bins = 50)
plt.show()
칸의 수를 50개로 설정하였더니, 데이터의 분포가 더 정교하게 보이는 듯 합니다.
아래와 같이 bins 인자로 구간을 수동 설정하는 것도 가능합니다.
또한, edgecolor 인자로 각 구간을 구분 짓는 선의 색깔을 입힐 수 있습니다.
plt.hist(data, color = 'green', alpha = 0.4, bins = [-3, -1, -0.5, 0, 0.5, 1, 3], edgecolor='black')
plt.show()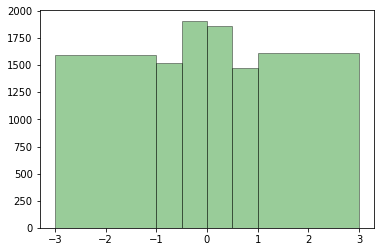
구간의 범위를 수동 설정하는 경우, 각 구간의 크기가 일정할 필요는 없습니다.
경계값의 경우는 작은쪽에 포함되어 들어갑니다.
즉, 위의 경우는 [-3, -1), [-1, -0.5) 처럼 구간이 나뉩니다.
파이썬 히스토그램 범위 설정, 누적 분포, histtype 지정
이상치 데이터가 음수쪽에 포함되어있는 것으로 보여, 정규분포에서 추출한 데이터지만,
오른쪽으로 치우친듯한 그래프 모양으로 그려지고 있습니다.
range인자를 이용하여, -3 ~ 3 사이로 범위를 제한해보도록 하겠습니다.
plt.hist(data, color = 'green', alpha = 0.4, bins = 50, range = [-3, 3], edgecolor = 'black')
plt.show()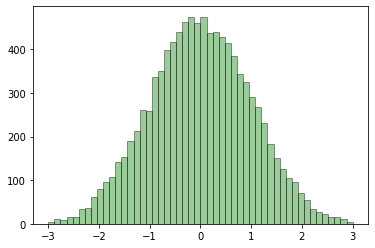
이제 더 정교한 정규분포 모양의 그래프가 그려진 것으로 보입니다.
누적 히스토그램을 그리고 싶은 경우는 cumulative 인자를 True로 설정해주시면 됩니다.
plt.hist(data, color = 'green', alpha = 0.4, bins = 50, range = [-3, 3],
edgecolor = 'black', cumulative = True)
plt.show()
히스토그램의 종류를 histtype인자를 통하여 변경할 수 있습니다.
기본 값은 'bar'이며, 'barstacked', 'step', 'stepfilled' 형태의 히스토그램도 지원합니다.
여기서는 'step' 타입의 히스토그램을 그려보도록 하겠습니다.
plt.hist(data, color = 'green', alpha = 0.4, bins = 50, range = [-3, 3], histtype = 'step')
plt.show()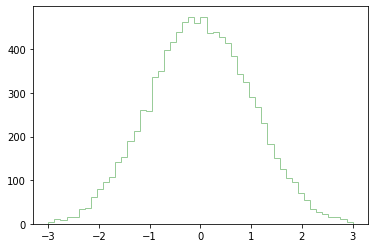
히스토그램 겹치기, y축 빈도로 설정하기, 범례 표시하기
두 개이상의 히스토그램을 겹치는 것도 가능합니다. plt.show() 실행 이전에
plt.hist()를 여러번 실행시켜주면 됩니다.
또한, label 변수로 각 히스토그램의 범례를 지정할 수 있습니다.
plt.legend() 함수를 이후에 실행하면 그래프에 범례가 출력됩니다.
density 변수를 True로 설정하면, 각 구간의 개수가 y축에서 표현되는 것이 아니라,
각 구간의 빈도가 표시되는 것으로 변경됩니다.
분포가 다른 데이터를 하나 더 추출해본 뒤, 두 데이터의 히스토그램 분포를
겹쳐서그린 예시를 살펴보도록 하겠습니다.
data2 = np.random.randn(10000) * 0.5
plt.hist(data, color = 'green', alpha = 0.2, bins = 50, range = [-3, 3], label = 'data1', density = True)
plt.hist(data2, color = 'red', alpha = 0.2, bins = 50, range = [-3, 3], label = 'data2', density = True)
plt.legend()
plt.show()
두 그래프가 초록색, 빨강색으로 동시에 표시되어 비교가 가능해졌으며,
y축은 개수가 아니라 빈도로 바뀐 것을 확인할 수 있었습니다.
x축, y축, 제목 등도 다른 그래프 종류처럼 지정이 가능하며,
여기서 다룬 파라미터 종류 외에도 히스토그램을 설정할 수 있는 인자는 더 다양합니다.
(대표적으로 weights, align, log, orientation, bottom, rwidth, stacked 등이 있습니다.)
'Python > Matplotlib' 카테고리의 다른 글
| [Matplotlib] 파이썬 그래프 여러개 다중 플롯(subplot) 초간단 설정 방법 (0) | 2021.12.31 |
|---|---|
| [Matplotlib] seaborn 이용 파이썬 box plot 그리기 (0) | 2021.12.05 |
| [Matplotlib] 파이썬 다중 막대 그래프 그리기 예제 (0) | 2021.11.30 |