넘파이 랜덤 추출 모듈 : np.random 함수 정리
이번 포스팅에서는 랜덤 추출시 많이 사용하는 np.random 모듈의 대표적인
함수들인 rand, random, randn, randint, choice 그리고 seed를 정하는 방법에
대하여 정리해보는 시간을 가지도록 하겠습니다.
0~1 사이 균일 분포 추출 함수 : rand, random
가장 먼저, 기본적으로 0~1 사이의 실수 값들을 균일 분포에서 추출해내는
rand와 random 함수에 대해서 살펴보겠습니다.
rand함수의 사용법은 간단합니다.
np.random.rand()로 작성하면 값 1개가 추출되고,
np.random.rand()의 괄호 내에 dimension을 적으면, 해당 dimension을 가진
넘파이 array가 생성되며, 추출되었던 값들이 부여됩니다.
사용 코드 예시를 살펴보겠습니다.

모두 0~1 사이의 값들이 부여된 제안된 차원의 array가 추출된 것을 확인할 수 있습니다.
히스토그램으로 추출 결과를 세부적으로 살펴보겠습니다.
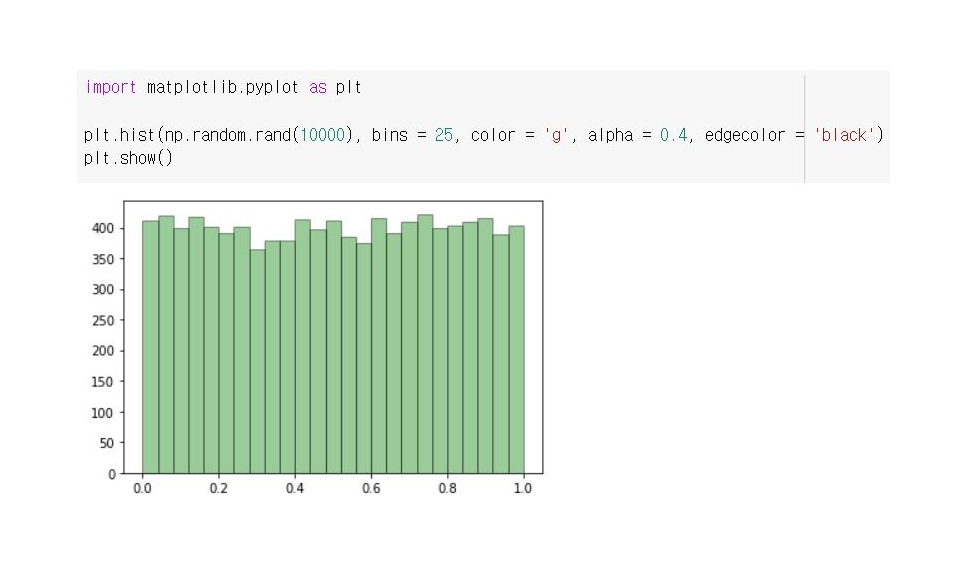
데이터들이 0~1 사이 구간에 제법 균등하게 분포하여 샘플링된 것을 확인해보았습니다.
np.random.random 함수는 rand 함수와 거의 동일하나, 원하는 차원의 형태를
튜플 자료형으로 넣어주어야 한다는 차이점이 있습니다.
즉, 5 * 3 차원의 array를 랜덤 추출할 때,
np.random.rand(5, 3) 과
np.random.random((5, 3)) 의 차이라고 생각하시면 됩니다.
예시 코드와 추출 결과 히스토그램도 마찬가지로 살펴보겠습니다.


rand 함수처럼 0~1 사이 구간에 균등하게 데이터들이 분포되어 추출된 것을
확인할 수 있습니다.
표준 정규 분포 추출 함수 : randn
이번에는 평균 0, 표준편차 1을 가지는 표준 정규 분포 내에서
임의 추출하는 함수인 randn을 알아보겠습니다.
rand 함수와 마찬가지로 원하는 차원을 넣으면 해당 차원만큼
numpy array가 형성되어 추출된 값들이 반환됩니다.
실행 결과와 추출된 데이터들의 히스토그램 분포를 보겠습니다.


정규 분포의 특징 상, 이론상으로는 모든 실수의 값들이 출력될 수는 있겠지만,
실제 추출해보면 거의 -2 ~ 2 사이에 95% 이상의 데이터가 분포된 것을
확인해볼 수 있습니다.
정수 임의 추출 함수 : randint
때로는 정수를 대상으로만 임의로 추출하고 싶은 경우도 있습니다.
randint 함수는 (low, high, size) 순으로 인자가 구성되어 있는데요.
low~high - 1 사이 범위에서 정수를 임의 추출하여
원하는 dimension size의 넘파이 배열로 결과를 반환합니다.
high로 지정한 값은 추출값에 포함되지 않는 것에 유의해주세요.
추출 결과와 1~25 사이에서 추출된 결과 히스토그램을 살펴보겠습니다.

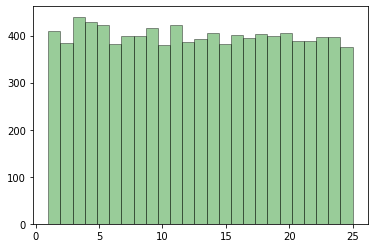
-5 ~ 5의 값들을 추출하고 싶으면, low = -5, high = 6으로 지정한 모습이 보였고,
추출 결과는 거의 균일하게 등장하는 것을 확인할 수 있었습니다.
원하는 조건 하에서 sampling : choice
원하는 집단에서 원하는 개수를 복원 추출 여부를 지정하고, 각 요소가 추출될
확률까지 지정할 수 있는 choice 함수를 살펴보겠습니다.
choice 함수의 구성은 다음과 같습니다.
np.random.choice(sample 집단, sample 개수, 복원 추출 여부(True/False), 확률 리스트)
sample 집단은 원하는 sampling되기 원하는 값들을 지정해주면 되는데,
정수로 지정시 0 ~ 해당 숫자 - 1 범위에서 정수 sampling이 됩니다.
sample 개수는 원하는 sample 결과의 dimension을 정수(1차원의 경우) 혹은
튜플(2차원 이상의 경우)로 지정해주시면 됩니다.
복원 추출 여부는 True인 경우 앞에서 등장한 값이 또 뽑히고,
False인 경우는 앞에서 등장한 값은 다시 등장하지 않습니다.
확률 리스트는 생략시 모든 sample 집단의 요소가 균등한 확률로 추출되고,
각 요소에 대한 확률을 지정하여 리스트 형태로 넣어주면 해당 확률을
반영하여 추출을 하게 됩니다.(단, 모든 확률의 합은 1이 되어야 합니다.)
소스 코드 예시를 살펴보겠습니다.

첫 번째 case는 0~9 사이 숫자에서 3개의 숫자를 복원 추출로 샘플링한 결과이고,
두 번째 case는 4가지의 문자열 중 5개를 p의 확률 분포로 복원 추출한 결과입니다.
추출 결과 고정 : seed
np.random 모듈의 추출 결과를 고정하려면 np.random 모듈에서 제공하는 seed 함수를
써야만 합니다.(일반 random 모듈의 random.seed는 적용되지 않습니다.)
np.random.seed(정수) 형태로 사용하면 되며, seed를 설정한 이후 출력 값들이
고정되게 됩니다.
사용 예시를 살펴보겠습니다.
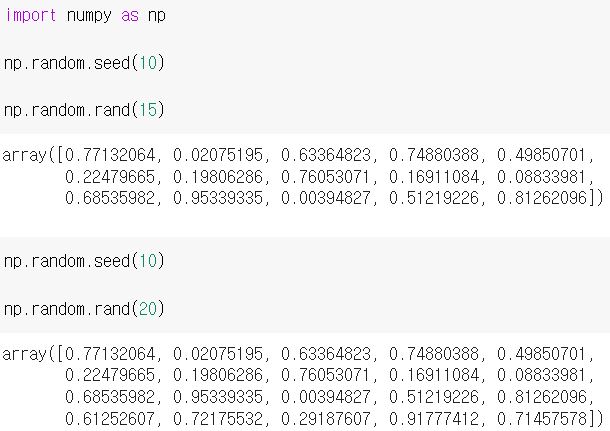
첫 15개 숫자가 seed = 10 값 지정 후, 완전히 동일한 것을 확인할 수 있었습니다.
이 외에도 np.random 모듈에서 제공하는 함수는 더 다양하지만, 이 정도에서
대표적으로 사용되는 함수들에 대한 글을 마무리해보도록 하겠습니다. 감사합니다.
'Python > Numpy' 카테고리의 다른 글
| [Numpy] 최대값, 최소값 함수 np.max vs np.maximum 차이 (np.min과 np.minimum) (0) | 2021.12.23 |
|---|---|
| [Numpy] 배열 쌓기 : np.hstack, np.vstack, np.concatenate 차이 비교 (0) | 2021.12.12 |
| [Numpy] np.where 사용법 : 조건 만족하는 위치 인덱스 찾기 (0) | 2021.12.02 |