0. 논문 개요
제목: TabM: Advancing Tabular Deep Learning with Parameter-Efficient Ensembling
등재된 conference: ICLR 2025
요약: MLP에서 파라미터 일부분만 앙상블하는 효과로 빠르지만 강력한 성능을 내는 Table Domain에서의 딥러닝 모델
공식 깃허브 링크: https://github.com/yandex-research/tabm
1. 모델 구조
이해를 돕기 위해 단순 MLP 모델에서 시작하여, 한 단계씩 확장된 구조로 설명을 하고 있습니다.
- 1단계: MLP x k (전통적 앙상블): k개의 MLP 모델을 독립적으로 학습시킨 모델, 단순 MLP 1개만 사용한 경우보다 성능은 좋지만 다소 비효율적
- 2단계: TabM packed (Packed 앙상블): k개의 MLP 모델을 묶어서 동시에 학습, 앙상블 전체의 성능을 보며 학습 중단을 결정할 수 있어 성능에 유리하지만 여전히 모델은 k배로 큼
- 3단계: TabM naive (Batch 앙상블): 대부분의 가중치 부분을 공유하고, 일부분만 독립적으로 가중치를 가진 구조. 모델 크기가 획기적으로 줄고, 가중치 공유가 규제 역할을 수행할 수 있어 성능 향상에 도움
- 4단계: TabM mini: TabM naive에서 첫 번째 어댑터 부분이 결정적인 것을 확인하여 이 부분만 독립적으로 가중치를 가지고 나머지는 모두 가중치 공유하는 구조로 변경
- 5단계: 최종 TabM: 3단계의 TabM naive의 구조로 돌아가서 첫 어댑터 부분만 랜덤 초기화하고, 나머지 부분은 전부 1로 초기화. 이렇게되면 학습 초기에는 TabM mini처럼 동작하다가, 필요에 따라 다른 어댑터들이 학습 과정에서 점차 변화하여 표현력을 키울 수 있음

위 이미지에서 표현하는 구조는 다음과 같습니다.
- 좌측 상단: k번 입력을 받고, 독립적으로 모델 통과 후, 예측된 결과를 사용하는 상위 수준의 개념을 표현, 학습 시에는 k개의 예측을 각각 사용하여 loss를 계산하고, 테스트 시에는 k개의 예측을 평균 내서 결과를 사용
- 우측 상단: 2단계 구조인 TabM packed를 표현, W와 b 부분이 k개의 모델에서 각각 독립적으로 가짐
- 좌측 하단: 최종 TabM 구조, 3단계의 TabM naive 구조와도 같으며, 초록색 W 부분은 k개의 모델에서 공유, 파란색 부분은 k개의 모델에서 독립적으로 가지는 구조
- 우측 하단: 4단계 구조인 TabM mini를 표현, 처음 부분인 파란색 R만 k개의 모델에서 독립적으로 가지며, 뒤의 초록색 부분은 공통적으로 가지는 구조
또한, 성능과 효율성을 개선하기 위하여 다음과 같은 방법들을 추가로 적용하였습니다.
- Shared training batches: 앙상블 시, 각 서브모델이 서로 다른 랜덤 시드로 섞인 데이터 배치를 사용해 학습하는 것이 일반적이지만, k개의 서브모델이 완전히 동일한 학습 데이터 배치를 공유하도록 수정. 이렇게 해도 학습 성능 손실은 미미하지만 학습 속도가 크게 향상 가능
- Non-linear feature embeddings: 표 데이터의 연속형 feature를 그냥 사용하는 대신, 신경망이 더 잘 이해할 수 있는 고차원 벡터로 임베딩하는 기법인데, 여기서는 piecewise-linear embeddings이라는 기법을 추가로 적용
- Deep Ensemble: 앙상블 모델을 또 앙상블하는 기법, TabM 5개를 독립적으로 학습 시켜 그 예측을 평균내는 방법을 적용 시도

위의 이미지는 기존 MLP 대비 상대적인 성능 개선의 폭을 나타냅니다. 우측 3개의 ♠, +, +x5의 notation은 각각 Shared training batches, Non-linear feature embeddings 및 Deep Ensemble을 나타냅니다.
2. 결과

46개의 데이터셋 전체의 순위를 매겼을 때, TabM 모델의 평균 순위가 가장 높았으며, GBDT 모델들과 비교해도 능가하는 경우가 많았음을 보여줍니다. 랜덤 분할 데이터셋 37개와 도메인 인지 분할 데이터셋 9개 모두에서도 비교적 일관되게 높은 성능을 보이고 있었습니다.

좌측은 모델 간 학습 시간을 비교한 그래프이고, 우측은 실시간으로 요청이 하나씩 들어오는 batch size = 1의 조건으로 추론 시간을 비교한 그래프입니다. TabM은 학습 및 추론 시간에서도 매우 빠른 경향성으로 효율성을 입증하였습니다.
3. 분석
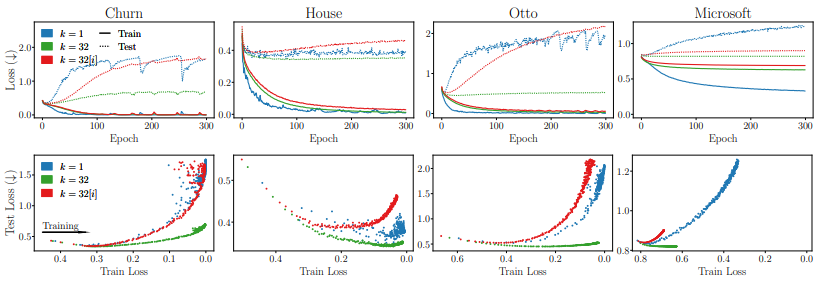
파란색은 MLP 1개, 빨간색은 TabM의 서브모델 각각의 평균, 초록색은 TabM의 전체 성능을 나타냅니다.
상단의 그래프에서는 4개의 데이터셋 모두에서 초록색이 모두 가장 낮은 test loss를 기록한 것을 보이고, 하단의 그래프에서는 train loss와 test loss의 상관관계로 과적합에 있어 초록색이 가장 robust함을 보였습니다.
즉, 각각의 서브모델은 과적합 측면에서 좋은 모델이 아닐 수 있으나, 이들이 팀이 되어 뭉치면 일반화 성능이 매우 뛰어난 모델이 될 수 있음을 시사합니다.

좌측의 그래프는 기존 MLP 대비 TabM의 서브모듈 중 가장 best의 성능(TabM[B])와 validation 성능 기준 최적의 서브모듈을 pruning하여 사용한 성능(TabM[G])를 나타낸 것입니다. 개인 서브모듈은 성능이 저조하지만 pruning을 하면 경량화된 버전으로도 유사한 성능을 낼 수 있었습니다.
우측의 그래프는 서브모듈 수에 따른 성능 변화입니다. 32~64개 정도의 구간을 지나면 서브모듈이 많아져도 성능 증가폭은 미미했습니다.
TabM 구조에서 Dead Neuron의 수도 일반 MLP에 비하여 약 절반 정도 적었습니다(29% -> 14%). 이는 TabM의 구조가 모델의 파라미터들을 훨씬 더 효율적으로 활용하도록 유도하여 전반적인 성능과 안정성에 기여함을 시사합니다.
이 글이 TabM 논문의 전반적인 이해에 도움이 되셨다면 좋겠습니다.
잘 봐주셔서 감사합니다.