이번 글에서는 파이토치로 DANN Loss를 활용한 Domain Adaptation을
간단하게 구현해보는 실습 코드 예제를 다루어보도록 하겠습니다.
DANN Loss는 class label 분류 학습과 함께 domain 분류를 진행하되,
domain 분류 layer의 gradient에 음수 배를 취하여 domain 간의 거리를 줄이도록
유도하는 학습을 통한 domain adaptation 방식으로 유명하게 사용되는 손실 함수 방식입니다.

여기에서는 예시로 두 숫자 글씨 데이터인 MNIST와 SVHN에 대하여 domain adaptation을
진행해보도록 하겠습니다.(아래 Figure와는 Source와 Target이 반대인 점을 유의해주세요.)

Step 1. 데이터셋 로드 및 전처리
먼저, MNIST와 SVHN 데이터셋을 불러오고 전처리를 해보겠습니다.
각 데이터셋을 28 * 28 픽셀의 흑백 이미지로 변환하기 위한 코드는 아래와 같습니다.
import torchvision.transforms as transforms
mnist_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (1.0,))
])
# RGB -> GRAY 및 28 * 28 사이즈 변환
svhn_transform = transforms.Compose([
transforms.Grayscale(num_output_channels=1),
transforms.CenterCrop(28),
transforms.ToTensor(),
transforms.Normalize((0.5,), (1.0,))
])
torchvision에서 두 데이터셋을 불러온 뒤, 위의 transforms 함수들을 적용하고
train, test 데이터셋 크기를 6만개 / 1만개로 맞추도록 하겠습니다.
from torchvision.datasets import MNIST, SVHN
import torch.utils.data as data_utils
import torch
download_root = './data'
train_mnist = MNIST(download_root, transform=mnist_transform, train=True, download=True)
test_mnist = MNIST(download_root, transform=mnist_transform, train=False, download=True)
svhn = SVHN(download_root, transform=svhn_transform, download=True)
# target domain 데이터 train 6만개, test 1만개 활용
train_indices = torch.arange(0, 60000)
test_indices = torch.arange(60000, 70000)
train_svhn = data_utils.Subset(svhn, train_indices)
test_svhn = data_utils.Subset(svhn, test_indices)
Step 2. 모델 구조 선언
여기서는 분류 모델로 아주 간단한 형태의 CNN 모델을 가정하겠습니다.
각 데이터 당 100차원의 벡터를 결과로 반환하는 CNN 모델은 다음과 같이 선언 가능합니다.
import torch.nn as nn
import torch.nn.functional as F
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=10, kernel_size=5, stride=1)
self.conv2 = nn.Conv2d(in_channels=10, out_channels=20, kernel_size=5, stride=1)
self.fc = nn.Linear(4 * 4 * 20, 100)
def forward(self, x):
x = F.relu(self.conv1(x)) # (batch, 1, 28, 28) -> (batch, 10, 24, 24)
x = F.max_pool2d(x, kernel_size=2, stride=2) # (batch, 10, 24, 24) -> (batch, 10, 12, 12)
x = F.relu(self.conv2(x)) # (batch, 10, 12, 12) -> (batch, 20, 8, 8)
x = F.max_pool2d(x, kernel_size=2, stride=2) # (batch, 20, 8, 8) -> (batch, 20, 4, 4)
x = x.view(-1, 4 * 4 * 20) # (batch, 20, 4, 4) -> (batch, 320)
x = F.relu(self.fc(x)) # (batch, 320) -> (batch, 100)
return x # (batch, 100)
이제 reverse gradient layer가 적용된 domain classifier과 0 ~ 9 숫자 class를 구분할
label classifier 구조를 선언하겠습니다. 더 복잡한 구조의 classifier로 구현해도 좋습니다.
(input은 CNN 결과인 100차원 벡터입니다.)
class GradReverse(torch.autograd.Function):
def forward(self, x):
return x.view_as(x)
def backward(self, grad_output): # 역전파 시에 gradient에 음수를 취함
return (grad_output * -1)
class domain_classifier(nn.Module):
def __init__(self):
super(domain_classifier, self).__init__()
self.fc1 = nn.Linear(100, 10)
self.fc2 = nn.Linear(10, 1) # mnist = 0, svhn = 1 회귀 가정
def forward(self, x):
x = GradReverse.apply(x) # gradient reverse
x = F.leaky_relu(self.fc1(x))
x = self.fc2(x)
return torch.sigmoid(x)
class label_classifier(nn.Module):
def __init__(self):
super(label_classifier, self).__init__()
self.fc1 = nn.Linear(100, 25)
self.fc2 = nn.Linear(25, 10) # class 개수 = 10개
def forward(self, x):
x = F.leaky_relu(self.fc1(x))
x = self.fc2(x)
return x
이제 위에서 선언한 두 종류의 classifier를 CNN과 연계하여 장착한
최종 분류 모델의 구조는 아래와 같이 구현이 가능합니다.
class DANN_CNN(nn.Module):
def __init__(self, CNN):
super(DANN_CNN, self).__init__()
self.cnn = CNN() # CNN 구조 모델 받아오기
self.domain_classifier = domain_classifier() # 도메인 분류 layer
self.label_classifier = label_classifier() # 숫자 0 ~ 9 클래스 분류 layer
def forward(self, img):
cnn_output = self.cnn(img) # (batch, 100)
domain_logits = self.domain_classifier(cnn_output) # (batch, 100) -> (batch, 1)
label_logits = self.label_classifier(cnn_output) # (batch, 100) -> (batch, 10)
return domain_logits, label_logits
Step 3. Loss 함수 선언
domain 분류 및 class 분류 loss를 혼합한 DANN loss 함수는 다음과 같이 구현이 가능합니다.
이 때, alpha는 domain 분류 loss 함수의 가중치로 하이퍼파라미터입니다.
class DANN_Loss(nn.Module):
def __init__(self):
super(DANN_Loss, self).__init__()
self.CE = nn.CrossEntropyLoss() # 0~9 class 분류용
self.BCE = nn.BCELoss() # 도메인 분류용
# result : DANN_CNN에서 반환된 값
# label : 숫자 0 ~ 9에 대한 라벨
# domain_num : 0(mnist) or 1(svhn)
def forward(self, result, label, domain_num, alpha = 1):
domain_logits, label_logits = result # DANN_CNN의 결과
batch_size = domain_logits.shape[0]
domain_target = torch.FloatTensor([domain_num] * batch_size).unsqueeze(1).to(device)
domain_loss = self.BCE(domain_logits, domain_target) # domain 분류 loss
target_loss = self.CE(label_logits, label) # class 분류 loss
loss = target_loss + alpha * domain_loss
return loss
Step 4. Training
모델 학습 함수의 코드 스니펫은 아래와 같습니다.
learning rate, alpha, optimizer, scheduler 종류 등을 다양하게 변경하여 적용이 가능합니다.
from torch.optim.lr_scheduler import LinearLR
from tqdm.notebook import tqdm
from torch.utils.data import DataLoader
batch_size = 64
# dataloader 선언
mnist_loader = DataLoader(dataset=train_mnist,
batch_size=batch_size,
shuffle=True)
svhn_loader = DataLoader(dataset=train_svhn,
batch_size=batch_size,
shuffle=True)
device = torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu')
my_cnn = CNN()
model = DANN_CNN(my_cnn).to(device)
loss_fn = DANN_Loss().to(device)
epochs = 10
model.train()
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3, weight_decay=0.01)
scheduler = LinearLR(optimizer, start_factor=1.0, end_factor=0.0, total_iters=epochs * len(mnist_loader))
alpha = 0.5
for i in range(1, epochs + 1):
total_loss = 0
for step in tqdm(range(len(mnist_loader))):
# mnist, svhn에서 1 batch씩 가져오기
source_data = iter(mnist_loader).next()
target_data = iter(svhn_loader).next()
# 각 batch 내 데이터 : 0번은 이미지 픽셀 값, 1번은 0 ~ 9 class 라벨 값
mnist_data = source_data[0].to(device)
mnist_target = source_data[1].to(device)
svhn_data = target_data[0].to(device)
svhn_target = target_data[1].to(device)
# 순전파 결과 구하기
source_result = model(mnist_data)
target_result = model(svhn_data)
# 순전파 결과, class label, domain label(0 = mnist, 1 = svhn), alpha 순서
source_loss = loss_fn(source_result, mnist_target, 0, alpha = alpha)
target_loss = loss_fn(target_result, svhn_target, 1, alpha = alpha)
loss = source_loss + target_loss
total_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step()
print('Epoch : %d, Avg Loss : %.4f'%(i, total_loss / len(mnist_loader)))
Step 5. class 분류 정확도 성능 테스트
학습이 완료된 모델에 대하여 0 ~ 9 숫자 label의 분류 정확도를 측정해보겠습니다.
아래의 코드로 측정이 가능한데, 모델이 비교적 간단하고 seed를 고정하지 않았기에
실행 시마다 결과는 크게 달라질 수 있습니다.
batch_size = 64
mnist_loader_test = DataLoader(dataset=test_mnist,
batch_size=batch_size)
svhn_loader_test = DataLoader(dataset=test_svhn,
batch_size=batch_size)
model.eval() # 테스트 모드로 전환
m_correct = 0
s_correct = 0
for step in tqdm(range(len(mnist_loader_test))):
source_data = iter(mnist_loader_test).next()
target_data = iter(svhn_loader_test).next()
mnist_data = source_data[0].to(device)
mnist_target = source_data[1].to(device)
svhn_data = target_data[0].to(device)
svhn_target = target_data[1].to(device)
# domain 분류와 관련된 logits은 사용하지 않기에 _로 받아서 처리
_, mnist_logits = model(mnist_data)
_, svhn_logits = model(svhn_data)
# 정확도 산출을 위하여 정답 개수 누적
m_correct += torch.sum(torch.argmax(mnist_logits, 1) == mnist_target).item()
s_correct += torch.sum(torch.argmax(svhn_logits, 1) == svhn_target).item()
print('MNIST Test Accuracy : %.2f%%'%(m_correct * 100 / (len(mnist_loader_test) * batch_size)))
print('SVHN Test Accuracy : %.2f%%'%(s_correct * 100 / (len(svhn_loader_test) * batch_size)))
MNIST는 98% 이상의 정확도로 비교적 분류가 잘 되었음에 비하여,
SVHN은 81% 정도의 정확도로 다소 분류가 어려운 데이터셋임을 확인하였습니다.
Step 6. Domain Embedding Space 시각화
DANN Loss를 통하여 두 domain의 임베딩 space가 가까워졌는지를 살펴보겠습니다.
우선, 250개씩 데이터를 골라 CNN output인 100차원 벡터를 구해보겠습니다.
# 가장 앞 batch의 250개씩의 데이터만 샘플링
mnist_loader = DataLoader(dataset=train_mnist,
batch_size=250,
shuffle=True)
svhn_loader = DataLoader(dataset=train_svhn,
batch_size=250,
shuffle=True)
source_data = iter(mnist_loader).next()
target_data = iter(svhn_loader).next()
mnist_data = source_data[0].to(device)
mnist_target = source_data[1].to(device)
svhn_data = target_data[0].to(device)
svhn_target = target_data[1].to(device)
# 학습된 모델의 CNN 부분만 활용(100차원 임베딩 벡터를 받아오는 과정)
mnist_vector = model.cnn(mnist_data)
svhn_vector = model.cnn(svhn_data)
이제, 임베딩 결과를 가져와 2차원 t-SNE 임베딩을 구하는 코드는 다음과 같습니다.
import pandas as pd
import numpy as np
from sklearn.manifold import TSNE
df = pd.DataFrame(np.concatenate([mnist_vector.cpu().detach().numpy(), svhn_vector.cpu().detach().numpy()], 0))
tsne_np = TSNE(n_components = 2).fit_transform(df)
tsne_df = pd.DataFrame(tsne_np, columns = ['component 0', 'component 1'])
구한 t-SNE 임베딩 결과를 2차원 공간에 시각화하는 코드는 아래와 같았습니다.
import matplotlib.pyplot as plt
tsne_df_0 = tsne_df.loc[:250]
tsne_df_1 = tsne_df.loc[250:]
plt.scatter(tsne_df_0['component 0'], tsne_df_0['component 1'], color = 'red', label = 'MNIST', alpha = 0.5)
plt.scatter(tsne_df_1['component 0'], tsne_df_1['component 1'], color = 'blue', label = 'SVHN', alpha = 0.5)
plt.title('alpha = 1.0')
plt.xlabel('component 0')
plt.ylabel('component 1')
plt.legend()
plt.show()
alpha = 1일 때와 0일 때 두 도메인 간 임베딩 공간 차이 예시는 아래와 같았습니다.
(학습률을 0.05로 높였던 결과이며, 실행 시 마다 결과가 크게 달라질 수 있습니다.)
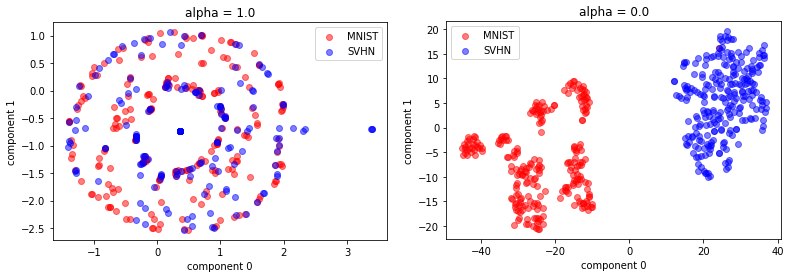
DANN loss 적용 결과 두 domain 간의 거리가 가까워졌음을 확인할 수 있었습니다.
'Python > Pytorch' 카테고리의 다른 글
| [Pytorch] 파이토치 RNN 계열 layer 원리 이해해보기 (0) | 2022.11.20 |
|---|---|
| [Pytorch] 파이토치 과적합 방지(Early Stopping) 구현 방법 정리 (0) | 2022.09.08 |
| [Pytorch] 텐서를 넘파이 배열, 리스트로 변환하는 방법 정리 (1) | 2022.08.12 |