파이썬 사이킷런 정확도, F1 score, 혼동 행렬 함수 사용법
파이썬 scikit-learn 모듈에서 제공하는 정확도 구현 함수인 accuracy_score,
F1 점수 함수인 f1_score(precision_score, recall_score 포함), 그리고
혼동 행렬 함수인 confusion_matrix에 대하여 간단히 정리해보도록 하겠습니다.
이해를 돕기 위하여, 실제 라벨 y_true와 예측 라벨 y_pred가 아래와 같이 등장한 상황을
가정해보도록 하겠습니다.
y_true = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1] # 실제 라벨 가정
y_pred = [0, 0, 0, 0, 1, 1, 1, 1, 0, 0] # 예측 라벨 가정참고로, 여기서는 y_true와 y_pred의 자료형은 리스트로 가정하였지만,
numpy array 혹은 pandas Series 등의 자료형으로 구성되었더라도 무방합니다.
정확도 함수 : accuracy_score
정확도(accuracy)는 실제 라벨과 예측 라벨이 일치하는 비율을 나타낸 지표로
가장 대표적인 머신러닝 성능평가 지표입니다.
사이킷런의 accuracy_score 함수에서는 실제 라벨과 예측 라벨 결과를
차례대로 input으로 넣으면 정확도를 계산하여 반환해줍니다.
from sklearn.metrics import accuracy_score
accuracy_score(y_true, y_pred) # 0.7
F1 점수, 정밀도, 재현율 함수 : f1_score, precision_score, recall_score
단순한 라벨 결과의 일치 여부 뿐만 아니라
음성과 양성 라벨 내에서의 정확도를 각각 계산하여 이를 반영한 성능평가 지표인
F1 score, 정밀도 및 재현율에 관한 함수도 파이썬 사이킷런에서 지원하고 있습니다.
(각각 f1_score, precision_score, recall_score 함수에 구현되어 있습니다.)

두 라벨이 0과 1로 이루어진 경우에는 기본적으로 0을 음성, 1을 양성으로 놓고 계산합니다.
이 세 함수의 기본 사용법도 실제 라벨과 예측 라벨을 순서대로 input으로 주시면 됩니다.
from sklearn.metrics import f1_score, precision_score, recall_score
f1_score(y_true, y_pred) # 0.6666666666666665
precision_score(y_true, y_pred) # 0.75
recall_score(y_true, y_pred) # 0.6참고로, 양성 기준 라벨을 변경하고 싶다면 pos_label 인자를 설정해주시면 되며(기본 값 = 1),
라벨 종류가 3개 이상인 경우에는 average 인자에 계산 방법의 기준을 설정해주시면 됩니다.
이에 대한 상세한 내용은 아래의 사이킷런 공식 document를 참고해주세요.
sklearn.metrics.f1_score
Examples using sklearn.metrics.f1_score: Probability Calibration curves Probability Calibration curves, Precision-Recall Precision-Recall, Semi-supervised Classification on a Text Dataset Semi-supe...
scikit-learn.org
혼동 행렬 함수 : confusion_matrix
각 라벨의 예측 결과 분포를 표의 형태로 정리하여 쉽게 알아볼 수 있는 혼동 행렬도
사이킷런 내에서 confusion_matrix 함수로 지원하고 있습니다.
사용 방법은 위의 함수들과 동일하며, 결과는 기본적으로 numpy array 형태로 반환됩니다.
from sklearn.metrics import confusion_matrix
confusion_matrix(y_true, y_pred)
'''
array([[4, 1],
[2, 3]])'''만일, 혼동 행렬 결과를 더 명료하게 나타내고 싶다면
아래의 예시 코드처럼 판다스의 기능을 통하여 데이터프레임 형태로 변환할 수도 있습니다.
import pandas as pd
mat = confusion_matrix(y_true, y_pred)
df = pd.DataFrame(mat, index = ['Negative(true)', 'Positive(true)'], columns = ['Negative(pred)', 'Positive(pred)'])
df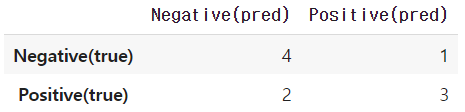
'Python > Sklearn' 카테고리의 다른 글
| 파이썬 XGBoost 분류기(XGBClassifier) 실습 코드 예제 (0) | 2022.05.24 |
|---|---|
| [Sklearn] 파이썬 K-Fold 교차 검증 예제(KFold, StratifiedKFold 함수) (0) | 2022.03.20 |
| [Sklearn] 파이썬 TF-IDF 구하기, 코사인 유사도로 비슷한 문서 찾기 (2) | 2022.02.22 |