Min-Hashing 기반 LSH 기법 설명
안녕하세요. 이번 시간에는 지난 번에 다룬 MinHash를 기반으로
유사한 문서 쌍을 빠르게 근사하여 찾을 수 있는 알고리즘인
LSH(Locality-Sensitive Hashing)에 대해서 다루어보도록 하겠습니다.
참고로, 이 글은 MinHash의 원리를 알고있음을 가정하고 설명할 예정이므로
해당 알고리즘에 대한 설명이 필요하신 분들은 아래 링크의 이전 글을 참고해주세요.
Min-Hashing이란?
MinHash 알고리즘 설명 안녕하세요. 이번 시간에는 데이터 마이닝 분야에서 문서 등 자료형 간의 유사도를 빠른 시간 내에 쉽게 근사하여 비교할 수 있는 Min-Hashing 알고리즘에 대해서 이해해보도
jimmy-ai.tistory.com
LSH 기본 가정
우선, 지난 포스팅에서 다루었던 각 문서에 MinHash를 적용한 결과를 다시 가져와보겠습니다.
참고로, 이 MinHash 결과를 앞으로는 signature이라고 명칭하겠습니다.

6개의 Signature가 2개의 행씩 3개의 band로 쪼개진 상황을 가정했습니다.
앞으로 LSH의 원리를 설명할 때, band의 개수를 b,
각 band 내 포함된 row(signature)의 개수를 r로 가정하고 설명하겠습니다.
Bucket Hashing
Bucket Hashing은 LSH에서 핵심이 되는 기술로, 각 band 내 signature의 조합을
임의의 bucket에 hashing하여 같은 signature여부를 간접적으로 따지는 방법을 의미합니다.
각 band마다 새로운 bucket에 hashing을 진행하게 되는데,
band 2의 경우 A와 B 문서는 signature의 조합이 모두 0, 0으로
같은 signature 조합을 가지고 있어, 같은 bucket에 두 문서가 포함되었습니다.
반면, band 1의 경우는 같은 signature 조합이 없어 모두 다른 bucket으로 배정되었습니다.
여기서 중요한 점은, LSH에서는 두 문서가 단 1개의 band에서라도 같은 bucket으로 해싱되면,
이 두 문서는 유사한 문서로 취급하게 된다는 가정입니다.
LSH 장점
그렇다면 굳이 직접 모든 signature 쌍을 비교하는 방법을 쓰지 않고,
Bucket Hashing을 이용하여 유사 문서를 찾는 이유는 무엇일까요?
만일, 총 10만개의 문서가 있다고 가정해보도록 하겠습니다.
그렇다면, 비교해야할 문서 pair의 조합 개수는 약 50억 가지에 육박합니다.
이렇게 pair의 개수가 O(n^2)에 비례하여 증가하여, 직접 모두 비교하기에는 큰 무리가 따릅니다.
여기서 문서 개수만큼의 hashing은 단지 O(n) 시간만 소요되므로,
Bucket Hashing은 pair 간 비교에서 시간을 크게 줄일 수 있는 큰 장점을 지니게 됩니다.
LSH 근사 정확도
Bucket Hashing을 이용한 근사 방법은 시간이 크게 절약되지만, 근사 알고리즘이므로
실제로 유사한 데이터(문서) pair를 정확하게 찾아내지는 못할 수도 있습니다.
이는 b와 r의 관계에 따라 달라지게 되는데,
예를 들어, signature가 500개라면 5개의 band에 signature를 100개씩 넣을 수도 있지만,
10개씩만 signature를 묶어 band를 50개나 만들 수도 있습니다.
한 band 내 signature가 많아지면 유사한 문서 pair를 놓칠 확률이 높아지고,
band가 너무 많아지면 비슷하지 않은 문서가 유사 데이터로 묶일 가능성이 있습니다.
확률의 예시로, 유사도 t = 0.7 이상의 문서 pair를 찾는 상황에서,
r = 10, b = 20이라고 가정해보겠습니다.(총 200개의 signature)
유사도 0.7인 문서 쌍이 10개의 signature에서 동일한 값 : (0.7)^10 = 0.028
20개의 band에서 해당 문서 쌍이 모두 다른 bucket 할당 : (1 - 0.028)^20 = 0.564
즉, 약 56.4%의 확률로 유사한 문서 쌍을 놓치게 되는 예시를 의미하였습니다.(False Negative)
이번엔 유사도 t = 0.4인 문서가 유사 pair로 분류될 확률도 구해보겠습니다.
유사도 0.4인 문서 쌍이 10개의 signature에서 동일한 값 : (0.4)^10 = 0.0001
20개의 band에서 해당 문서 쌍이 모두 다른 bucket 할당 : (1 - 0.0001)^20 = 0.998
단 0.2%의 확률로만 비슷한 데이터로 오분류된다는 것을 의미했습니다.(False Positive)
이상적인 t에 따른 비슷한 문서 분류 확률 curve와 일반화된 식은 아래와 같습니다.
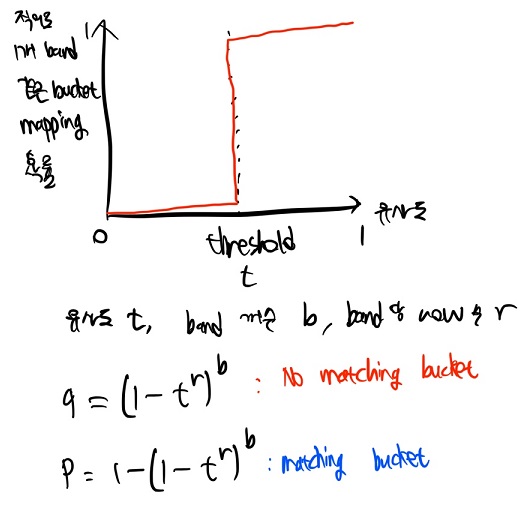
일반화된 식을 기준으로 위음성 - 위양성 trade-off를 따진 뒤,
b와 r을 적절하게 결정하여 LSH를 적용해주시면 최적의 결과를 얻을 수 있습니다.
'컴퓨터공학 > Data Mining' 카테고리의 다른 글
| Min-Hashing이란? (2) | 2022.02.03 |
|---|---|
| [그래프 이론] Modularity 뜻, 계산 예시(그래프 분할 평가) (0) | 2021.11.07 |