Groupby 함수, 멀티인덱스
파이썬 데이터 분석 툴인 Pandas를 사용하다보면 groupby 기능을 자주 사용하게 되고,
두 가지 이상의 범주로 groupby를 실행한 경우, 자동으로 멀티인덱스가 적용되어,
다음과 같이 뭉쳐있는 데이터 프레임의 형태를 살펴볼 수 있다.
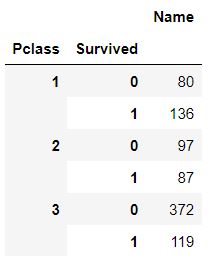
해당 데이터 셋은 kaggle에서 제공하는 타이타닉 데이터셋을 사용하였고,
다음과 같이 Pclass와 Survived 열로 groupby를 실행한 결과이다.
df = pd.DataFrame(train.groupby(['Pclass', 'Survived'])['Name'].count())우리는 다음과 같이 각 행이 나누어져있고, 인덱스가 초기화된 결과를 얻고 싶을 때가 있다.
이후 인덱싱이나 다른 작업에 넘길때 일반 데이터프레임처럼 간주할 수 있게되기 때문이다.

reset_index() 함수
사실 이 작업은 코드 한줄이면 마무리되는 간단한 작업인데, 이 기능을 잘 모를 경우, 헤매는 경우가 많을 수 있다.
groupby된 데이터 프레임에서 인덱스를 재정렬하여 나누어진 행을 만드는 것은 다음 코드 한줄이면 해결된다.
df = df.reset_index()판다스 내 reset_index() 함수를 사용하면 두 번째 표처럼 행이 분리된 데이터프레임의 결과를 살펴볼 수 있다.
참고로, level이라는 인자를 쓰면 다음과 같이 다른 column을 index로 가질 수 있다.

df = df.reset_index(level = 'Survived')주의해야 할 점은, level 인자로 지정한 반대의 column이 index로 지정된 것이다.
예를 들어, Pclass와 Survived 중 Pclass를 index로 취급하고 싶다면 Survived를 level 인자로 지정해주어야 한다.
reset_index 함수에는 더 다양한 기능이 있고, 이보다 더 복잡한 상황에서도 사용이 가능하다.
예를 들어, 사용하려는 경우의 상황이 3중 인덱스 이상일수도 있고, level을 디테일하게 적용하고 싶을 수도 있다.
또한, df = df.reset_index()처럼이 아니라 inplace = True 기능을 이용하면,
df.reset_index(inplace = True)처럼 변수 재선언 과정 없이 결과 반영이 가능하게 만들 수도 있다.
궁금하신 분들을 위하여 공식 document의 링크를 첨부하도록 하겠다.
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.reset_index.html
pandas.DataFrame.reset_index — pandas 1.3.4 documentation
next pandas.DataFrame.rfloordiv
pandas.pydata.org
'Python > Pandas' 카테고리의 다른 글
| [Pandas] 파이썬 판다스 그룹화 하기 : groupby 함수 (4) | 2021.11.16 |
|---|---|
| [Pandas] 파이썬 데이터프레임 열, 행에 함수 적용 - apply 함수 (0) | 2021.11.11 |
| [Pandas] 데이터프레임 인덱싱 loc, at 차이(iloc, iat 차이) (0) | 2021.11.05 |