반응형
Python의 판다스 모듈로 데이터프레임의 행들을 랜덤 추출할 수 있는
df.sample 기능에 대하여 사용 예제를 정리해보도록 하겠습니다.
이해를 돕기 위하여 아래의 데이터프레임 df에 대하여 행 샘플링을 진행해 보겠습니다.
import pandas as pd
df = pd.DataFrame({"이름" : ["AAA", "BBB", "CCC", "DDD", "EEE", "FFF", "GGG", "HHH", "III", "JJJ"],
"반" : [1, 1, 1, 1, 1, 2, 2, 2, 2, 2],
"점수" : [67, 100, 12, 85, 13, 92, 27, 5, 100, 98]})
df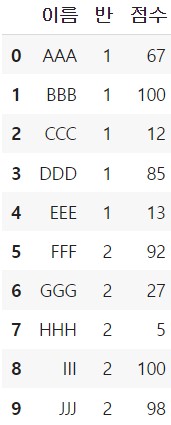
특정 개수 샘플링
df.sample(n) 형태로 간단하게 n개의 행들을 임의 추출하는 것이 가능합니다.
여기서 random_state 인자를 특정 정수로 지정 시 샘플링 결과가 고정됩니다.
df.sample(3)
# df.sample(3, random_state = 14) 샘플링 결과 고정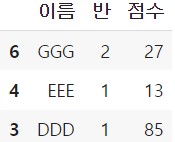
특정 비율 샘플링
df.sample(frac = r) 형태로 지정하여, 전체 행들 중 r만큼 비중의 행들을
랜덤 샘플링할 수 있습니다. 아래는 전체 중 절반의 행들을 임의 추출하는 예시입니다.
(개수와 비율 중 하나만 지정이 가능한 점을 유의해주세요.)
df.sample(frac = 0.5)
반응형
가중치 샘플링
각 행의 가중치를 다르게 설정하여 샘플링하는 것도 가능합니다.
weights 인자에 숫자로 구성된 특정 열을 지정하거나
리스트(배열) 형태로 원하는 가중치를 직접 지정할 수도 있습니다.
df.sample(5, weights = "점수")
# 가중치 직접 지정해서도 가능
# df.sample(5, weights = [0.4, 0.1, 0.1, 0.1, 0.1, 0.1, 0.05, 0.05, 0, 0])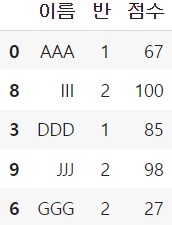
중복 허용 샘플링
replace 인자를 True로 지정 시, 이미 추출된 행이 중복하여 등장할 수 있습니다.
이 경우에는 n을 행 개수 초과로 하거나 frac 인자에 1보다 큰 수를 지정도 가능합니다.
df.sample(7, replace = True)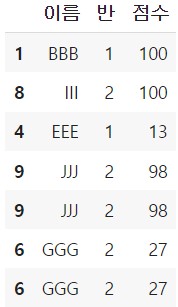
기타 df.sample 기능
axis 인자 : 1로 지정 시 행 대신 열 기준으로 랜덤 샘플링이 진행됩니다.
ignore_index 인자 : True로 설정 시 추출 결과의 인덱스가 0, 1, ..., n-1로 초기화됩니다.
'Python > Pandas' 카테고리의 다른 글
| [Pandas] 파이썬 판다스 isin 함수 및 not isin 조건 사용 방법 (0) | 2022.09.18 |
|---|---|
| [Pandas] 파이썬 판다스 요일 추출 방법 정리(weekday, day_name(), 한글 요일 이름) (0) | 2022.08.23 |
| [Pandas] 판다스 설치 / 버전 확인 / 버전 변경(업데이트, 다운그레이드) 방법 정리 (0) | 2022.08.15 |