반응형
Python scikit-learn word count method
파이썬의 사이킷런 모듈을 활용하여 단어의 개수를 손쉽게 셀 수 있는
CountVectorizer 메소드에 관하여 사용 예제를 간략하게 정리해보도록 하겠습니다.
우선, 아래와 같은 문서들의 리스트가 있다고 가정하고 문서별로 단어 개수를 세보겠습니다.
d1 = '바나나 사과 딸기 딸기 참외'
d2 = '수박 바나나 딸기 바나나 딸기'
d3 = '딸기 수박 참외 사과 사과 수박'
d4 = '사과 사과 사과 사과 참외 참외'
corpus = [d1, d2, d3, d4]
단어 개수 세기 기본 예시
CountVectorizer를 사용하여 단어 개수 벡터화를 진행해 보겠습니다.
기본 값으로 사용 시 공백 기준으로 단어를 나눠 개수를 카운팅하게 되며,
벡터화 객체 선언 후 코퍼스에 대한 벡터화를 진행하고 array로 변환하여 출력해주면 됩니다.
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer() # 벡터화 방법 선언(여기서는 기본 값)
result = vectorizer.fit_transform(corpus) # 코퍼스 벡터화(단어별 개수 카운팅)
print(result.toarray()) # array 변환 후 출력
[[2 1 1 0 1]
[2 2 0 1 0]
[1 0 2 2 1]
[0 0 4 0 2]]
이후, 출력 결과를 문서별로 보기 편하게 데이터프레임으로 변환하려면
아래와 같이 코드를 실행시켜주시면 됩니다.
import pandas as pd
# 단어 순서 조회
column_names = vectorizer.get_feature_names_out() #['딸기', '바나나', '사과', '수박', '참외']
# 데이터프레임 변환(인덱스 지정 포함)
df = pd.DataFrame(result.toarray(), columns = column_names, index = ['d1', 'd2', 'd3', 'd4'])
df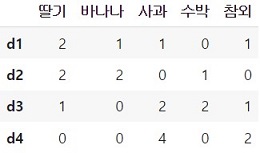
반응형
N-gram 단위 개수 세기
만일 n-gram 단위로 카운팅을 진행하고 싶다면 ngram_range 인자에 (시작, 끝 숫자) 형태로
input을 지정해주시면 됩니다.
예시로, 2-gram 단위 카운팅을 진행한 예시 코드는 다음과 같습니다.
vectorizer2 = CountVectorizer(ngram_range=(2, 2))
result2 = vectorizer2.fit_transform(corpus)
print(result2.toarray())
[[1 0 0 1 0 1 1 0 0 0 0 0 0 0]
[0 1 0 0 2 0 0 0 0 0 1 0 0 0]
[0 0 1 0 0 0 0 1 1 0 0 1 1 0]
[0 0 0 0 0 0 0 3 0 1 0 0 0 1]]
이후, 데이터프레임으로 변환하여 2-gram 단위로 등장한 횟수도 한 눈에 볼 수 있습니다.
column_names2 = vectorizer2.get_feature_names_out()
df2 = pd.DataFrame(result2.toarray(), columns = column_names2, index = ['d1', 'd2', 'd3', 'd4'])
df2
글자 단위 개수 세기
이번에는 문서별 단어 개수가 아니라 글자(character)를 기준으로 개수를 세보겠습니다.
이 경우 analyzer 인자를 'char'로 지정해주시면 됩니다.
vectorizer3 = CountVectorizer(analyzer='char')
result3 = vectorizer3.fit_transform(corpus)
print(result3.toarray())
[[4 1 2 2 2 1 0 1 0 1 1]
[4 0 2 4 2 2 1 0 1 0 0]
[5 2 1 0 1 0 2 2 2 1 1]
[5 4 0 0 0 0 0 4 0 2 2]]
글자 단위 카운팅 결과를 데이터프레임으로 보면 아래와 같이 나타납니다.
column_names3 = vectorizer3.get_feature_names_out()
df3 = pd.DataFrame(result3.toarray(), columns = column_names3, index = ['d1', 'd2', 'd3', 'd4'])
df3
'Python > Sklearn' 카테고리의 다른 글
| [Sklearn] 파이썬 ROC 커브, AUC 면적 구하기 예제 (0) | 2022.09.16 |
|---|---|
| [Sklearn] 파이썬 나이브 베이즈 분류기 구현 예제 (0) | 2022.06.13 |
| [Sklearn] 파이썬 Regularization : Lasso, Ridge, ElasticNet 적용하기 (0) | 2022.06.03 |