반응형
Python t검정, 회귀 분석 p value 값 구하기 방법 요약
파이썬에서 p-value 값을 계산해내는 방법들을
t-test와 회귀 분석의 경우에 대하여 간략하게 정리해보도록 하겠습니다.
p-value 값 찾기 : t-검정의 경우
ttest 함수 실행 후 반환 결과의 1번 인덱스(두 번째) 값에 p-value가 들어있으므로,
해당 값을 인덱싱해주시면 됩니다.
from scipy import stats
import numpy as np
X = np.random.random(50) # 데이터 가정
# X의 평균이 0인 경우에 대한 p-value
stats.ttest_1samp(X, 0)[1] # 4.530894030802283e-17
# X의 평균이 0.5인 경우에 대한 p-value
stats.ttest_1samp(X, 0.5)[1] # 0.7085841472065706참고로, 여기서의 p-value는 0.01, 0.05 등의 정해진 기준보다 낮다면 검정하려했던 평균 값과
일치한다고 보기 어렵다는 의미로 해석해주시면 됩니다.
각 상황별 상세한 t검정 함수에 대한 설명은 아래 글을 참고해주세요.
[Scipy] 파이썬 t-검정 정리 : 단일표본, 독립표본, 대응표본
파이썬 T-test 예제 안녕하세요. 이번 시간에는 파이썬 Scipy 라이브러리를 활용하여 단일, 독립 및 대응표본의 각 경우에 대해서 t 검정을 진행하는 방법을 다루어보도록 하겠습니다. 단일표본 t
jimmy-ai.tistory.com
반응형
p-value 값 찾기 : 회귀 분석의 경우
statsmodels 패키지를 활용한 회귀 분석 진행 후, summary 결과를 확인하시면
각 변수별 p-value 값을 확인하실 수 있습니다.
아래는 선형 회귀를 진행하고 각 변수별 p value를 알아본 예시입니다.
import pandas as pd
import statsmodels.api as sm
X1 = np.random.random(50)
X2 = np.random.random(50)
y = 3 * X1 - 2 * X2 + np.random.random(50)
df = pd.DataFrame({'X1' : X1, 'X2' : X2, 'y' : y}) # 데이터셋 가정
# 컬럼 이름을 기준으로 독립, 종속 변수 지정
X = df[['X1', 'X2']]
y = df['y']
model = sm.OLS(y, X).fit() # 회귀 모델 학습
model.summary() # 결과 출력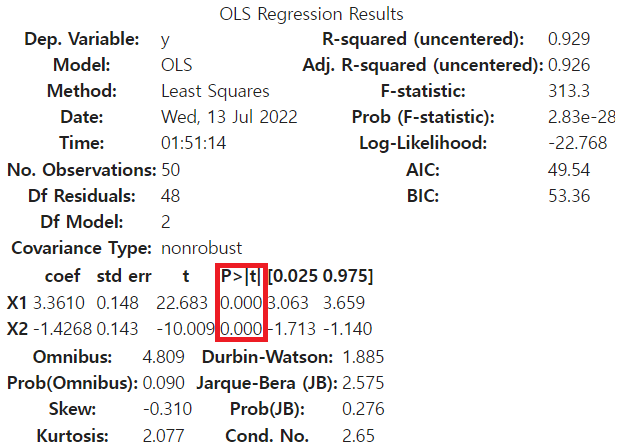
회귀 분석에서의 p value의 의미(빨간색 네모)는 각 독립 변수가 종속 변수의 예측 결과에
유의미한 영향을 끼쳤는지를 의미합니다. 즉, 정한 기준(0.01, 0.05 등)보다 낮다면
해당 변수(X1, X2)들은 예측 값(y)의 결과와 유의한 상관이 있다는 의미로 봐주시면 됩니다.
'Python > Scipy' 카테고리의 다른 글
| [Scipy] 파이썬 신뢰 구간 구하기 및 시각화 예제 (0) | 2022.09.28 |
|---|---|
| [Scipy] 파이썬 정규분포 확률밀도함수, 누적분포함수, 백분위수 찾기 : pdf, cdf, ppf (0) | 2022.06.04 |
| [Scipy] 파이썬 t-검정 정리 : 단일표본, 독립표본, 대응표본 (2) | 2022.02.27 |